Release 9.2
 Home |
 Book List |
 Contents |
 Master Index |
 Feedback |
| Oracle Ultra Search Online Documentation Release 9.2 |
|
 |
Related Topics |  |
 |
 |
|
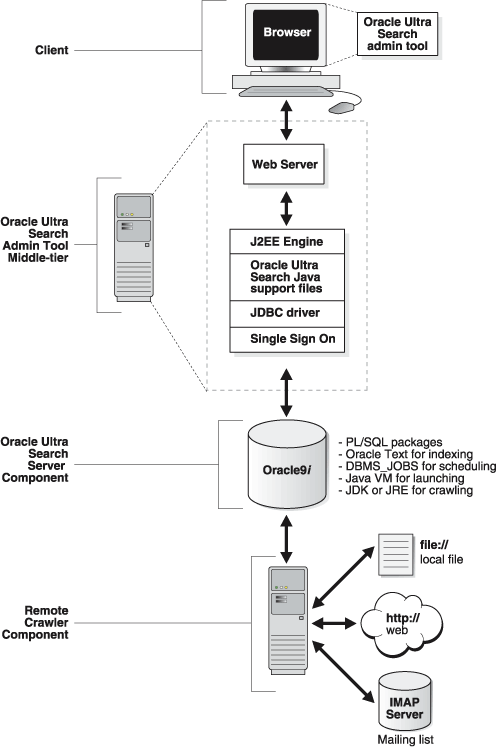
Oracle Ultra Search lets you index and search Web sites, database tables, files, mailing lists, Oracle9i Application Server (9iAS) Portals, and user-defined data sources. As such, you can use Oracle Ultra Search to build different kinds of search applications. Oracle Ultra Search has the following components:
The Ultra Search server component consists of the Ultra Search data dictionary, Ultra Search PL/SQL packages, Ultra Search crawler Java classes, and Oracle9i Text. Oracle9i Text provides the text indexing and search capabilities required to index and query data retrieved from your data sources, such Web sites or database tables.
For more information about configuring the server component, see Installing Oracle Ultra Search.
The administration tool is a Web application for configuring and scheduling the Ultra Search crawler. The administration tool is typically installed on the same machine as your Web server. You can access the administration tool from any browser in your intranet, directly as an Ultra Search database user, or as a single sign-on (SSO) user with a SSO server.
The Ultra Search administration tool and the Ultra Search query applications are part of the Ultra Search middle tier components module. However, the Ultra Search administration tool is independent from the Ultra Search query application. Therefore, they can be hosted on different machines to enhance security or scalability.
For more information, see About the Ultra Search Administration Tool.
The Ultra Search crawler is a Java process activated by your Oracle server according to a set schedule. When activated, the crawler spawns processor threads that fetch documents from various data sources. These documents are cached in the local file system. When the cache is full, the crawler indexes the cached files using Oracle Text. This index is used for querying.
Remote Crawler Component
You can run the crawler process on the same machine as your Ultra Search Oracle database. However, with such a setup, the crawler process might compete with the Oracle database for resources. For better performance, set up the crawler to run on one or more remote machines. Each machine is known as a remote crawler and must be configured so that it shares the cache, log, and email archive directories with the database machine.
For more information, see About the Ultra Search Crawler and Data Sources.
Ultra Search provides a Java API for querying indexed data. The API returns data with and without HTML markup. The HTML markup can help you build the following search engine Web interfaces:
- Basic search form
- Advanced search form
- Query result display
- Help page
- Feedback page
- Register URL
The Java API uses JDBC connection pooling for scalability.
For more information, see About the Ultra Search Query API
Ultra Search provides a Java API for accessing archived emails. The API is used by the Ultra Search query application to display emails. The API can also be used to build your own custom query application.
For more information, see About the Ultra Search Email API.
Ultra Search includes fully functional sample query applications to query and display search results. The sample query applications are shipped as a deployed J2EE Web application (sample.ear). This component depends on a J2EE container to host the Web pages, a JDBC driver, and Java Mail API for displaying email results. After the sample.ear file is deployed by the Oracle Containers for J2EE (OC4J), you see a set of JSP files that demonstrate the query API usage.
The sample query applications include a sample search portlet. The sample Ultra Search portlet demonstrates how to write a search portlet for use in Oracle 9iAS Portal.
An introduction to these applications is given with $ORACLE_HOME/ultrasearch/sample/sample_readme.htm.
For more information about the application, see About the Ultra Search Query Application.
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|