| Oracle® XML Developer's Kit Programmer's Guide 10g Release 1 (10.1) Part Number B10794-01 |
|





|
View PDF |
| Oracle® XML Developer's Kit Programmer's Guide 10g Release 1 (10.1) Part Number B10794-01 |
|
|
View PDF |
This chapter contains these topics:
XML has become the format for data interchange, but at the same time, a substantial amount of data resides in object-relational databases. It is therefore necessary to have the ability to transform this object-relational data to XML.
XML SQL Utility (XSU) enables you to do these transformations:
XSU can transform data retrieved from object-relational database tables or views into XML.
XSU can extract data from an XML document, and using a given mapping, insert the data into appropriate columns or attributes of a table or a view.
XSU can extract data from an XML document and apply this data to updating or deleting values of the appropriate columns or attributes.
When given a SELECT query, XSU queries the database and returns the results as an XML document.
Given an XML document, XSU can extract the data from the document and insert it into a table in the database.
XML SQL Utility functionality can be accessed in the following ways:
Through a Java API
Through a PL/SQL API
Through a Java command-line front end
Dynamically generates DTDs.
During generation, performs simple transformations, such as modifying default tag names for the ROW element. You can also register an XSL transformation that is then applied to the generated XML documents as needed.
Generates XML documents in their string or DOM representations.
Inserts XML into database tables or views. XSU can also update or delete records from a database object, given an XML document.
Generates complex nested XML documents. XSU can also store them in relational tables by creating object views over the flat tables and querying over these views. Object views can create structured data from existing relational data using object-relational infrastructure.
Generates an XML Schema given a SQL query.
Generates XML as a stream of SAX2 callbacks.
Supports XML attributes during generation. This provides an easy way to specify that a particular column or group of columns must be mapped to an XML attribute instead of an XML element.
Allows SQL identifier to XML identifier escaping. Sometimes column names are not valid XML tag names. To avoid this you can either alias all the column names or turn on tag escaping.
Supports XMLType columns in objects or tables.
|
See Also:
|
Important information about XSU:
|
Note: In Oracle9i,XMLGen was deprecated and is now no longer included with Oracle software. The replacements for XMLGEN are the packages DBMS_XMLQuery, used for XML generation, and DBMS_XMLSave, used for DML and data manipulation.
Migration is simple: the method names are identical. The new XSU for PL/SQL now contains more methods. All methods take the context handle as the first argument. |
XML SQL Utility (XSU) depends on the following components:
Database connectivity - JDBC drivers. XSU can work with any JDBC driver but it is optimized for Oracle JDBC drivers. Oracle does not make any guarantee or provide support for the XSU running against non-Oracle databases.
Oracle XML Parser, Version2 - xmlparserv2.jar. This file is included in the Oracle installations. xmlparserv2.jar is also part of the XDK Java components archive downloadable from Oracle Technology Network (OTN) Web site.
XSU also depends on the classes included in xdb.jar and servlet.jar. These are present in Oracle installations. These are also included in the XDK Java components archive downloadable from OTN.
XSU is on the Oracle software CD, and it is also part of the XDK Java components package available on OTN. The XSU comes in the form of two files:
$ORACLE_HOME/lib/xsu12.jar -- Contains all the Java classes that make up XSU. xsu12.jar requires a minimum of JDK1.2 and JDBC2
$ORACLE_HOME/rdbms/admin/dbmsxsu.sql -- This is the SQL script that builds the XSU PL/SQL API. Load xsu12.jar into the database before dbmsxsu.sql is executed.
By default, the Oracle installer installs the XSU on the hard drive in the locations specified in the previous bulleted paragraphs. It also loads the XSU into the database.
If XSU is not installed during the initial Oracle installation, it can be installed later. You can either use Oracle Installer to install the XSU and its dependent components, or you can download the latest XDK Java components from OTN.
To load the XSU into the database you need to take one of the following steps, depending on how you installed XSU:
Oracle Installer installation: Change directory to your ORACLE_HOME directory, then to rdbms/admin. Run initxml.sql.
OTN download installation: Change directory into the bin directory of the downloaded and expanded XDK tree. Then run script xdk load. Windows users run xdkload.bat.
XSU is written in Java, and can live in any tier that supports Java. XSU can be installed on a client system.
The Java classes that make up XSU can be loaded into a Java-enabled Oracle database. XSU contains a PL/SQL wrapper that publishes the XSU Java API to PL/SQL, creating a PL/SQL API. This way you can:
Write new Java applications that run inside the database and that can directly access the XSU Java API
Write PL/SQL applications that access XSU through its PL/SQL API
Access XSU functionality directly through SQL
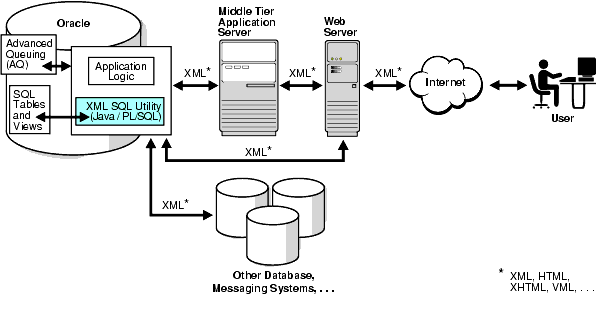
Figure 7-1 shows the typical architecture for such a system. XML generated from XSU running in the database, can be placed in advanced queues in the database to be queued to other systems or clients. The XML can be used from within stored procedures in the database or shipped outside through web servers or application servers.
In Figure 7-1, all lines are bi-directional. Since XSU can generate as well as save data, data can come from various sources to XSU running inside the database, and can be put back in the appropriate database tables.
Your application architecture may need to use an application server in the middle tier, separate from the database. The application tier can be an Oracle database, Oracle Application Server, or a third party application server that supports Java programs.
You can generate XML in the middle tier, from SQL queries or ResultSets, for various reasons. For example, to integrate different JDBC data sources in the middle tier. In this case you can install the XSU in your middle tier and your Java programs can make use of XSU through its Java API.
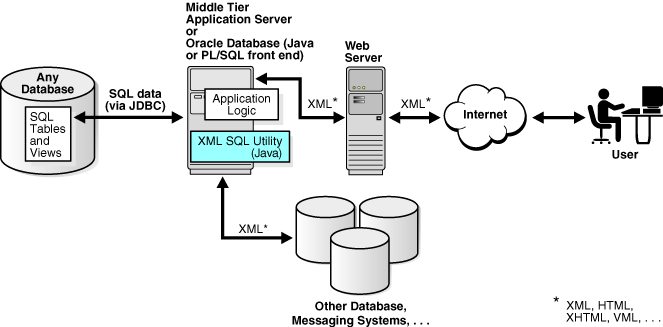
Figure 7-2, shows how a typical architecture for running XSU in a middle tier. In the middle tier, data from JDBC sources is converted by XSU into XML and then sent to Web servers or other systems. Again, the whole process is bi-directional and the data can be put back into the JDBC sources (database tables or views) using XSU. If an Oracle database itself is used as the application server, then you can also use the PL/SQL front-end instead of Java.
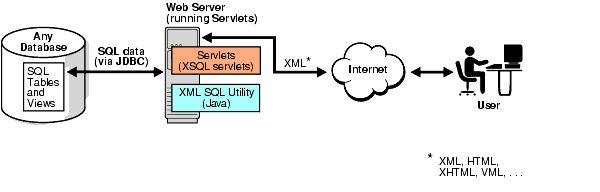
Figure 7-3 XSU can live in the Web server, as long as the Web server supports Java servlets. This way you can write Java servlets that use XSU to accomplish their task.
XSQL Servlet does just this. XSQL Servlet is a standard servlet provided by Oracle. It is built on top of XSU and provides a template-like interface to XSU functionality. If XML processing in the Web server is your goal, you can probably use the XSQL Servlet, as it will spare you from the intricate servlet programming.
This section describes the mapping or transformation used to go from SQL to XML or vice versa.
Consider table emp1:
CREATE TABLE emp1 ( empno NUMBER, ename VARCHAR2(20), job VARCHAR2(20), mgr NUMBER, hiredate DATE, sal NUMBER, deptno NUMBER );
XSU can generate an XML document by specifying the query:
select * from emp1:
<?xml version='1.0'?>
<ROWSET>
<ROW num="1">
<EMPNO>7369</EMPNO>
<ENAME>sMITH</ENAME>
<JOB>clerk</JOB>
<mgr>7902</mgr>
<HIREDATE>12/17/1980 0:0:0</HIREDATE>
<SAL>800</SAL>
<DEPTNO>20</DEPTNO>
</ROW>
<!-- additional rows ... -->
</ROWSET>
In the generated XML, the rows returned by the SQL query are enclosed in a ROWSET tag to constitute the <ROWSET> element. This element is also the root element of the generated XML document.
The <ROWSET> element contains one or more <ROW> elements.
Each of the <ROW> elements contain the data from one of the returned database table rows. Specifically, each <ROW> element contains one or more elements whose names and content are those of the database columns specified in the SELECT list of the SQL query.
These elements, corresponding to database columns, contain the data from the columns.
Here is a mapping against an object-relational schema: Consider the object type, AddressType. It is an object type whose attributes are all scalar types and is created as follows:
CREATE TYPE AddressType AS OBJECT ( street VARCHAR2(40), city VARCHAR2(20), state CHAR(2), zip VARCHAR2(10) );
The following type, EmployeeType, is also an object type but it has an empaddr attribute that is of an object type itself, specifically, AddressType. Employee Type is created as follows:
CREATE TYPE EmployeeType AS OBJECT ( empno NUMBER, ename VARCHAR2(20), salary NUMBER, empaddr AddressType );
The following type, EmployeeListType, is a collection type whose elements are of the object type, EmployeeType. EmployeeListType is created as follows:
CREATE TYPE EmployeeListType AS TABLE OF EmployeeType;
Finally, dept1 is a table with an object type column and a collection type column: AddressType and EmployeeListType respectively.
CREATE TABLE dept1 ( deptno NUMBER, deptname VARCHAR2(20), deptaddr AddressType, emplist EmployeeListType ) NESTED TABLE emplist STORE AS emplist_table;
Assume that valid values are stored in table, dept1. For the query select * from dept1, XSU generates the following XML document:
<?xml version='1.0'?>
<ROWSET>
<ROW num="1">
<DEPTNO>100</DEPTNO>
<DEPTNAME>Sports</DEPTNAME>
<DEPTADDR>
<STREET>100 Redwood Shores Pkwy</STREET>
<CITY>Redwood Shores</CITY>
<STATE>CA</STATE>
<ZIP>94065</ZIP>
</DEPTADDR>
<EMPLIST>
<EMPLIST_ITEM num="1">
<EMPNO>7369</EMPNO>
<ENAME>John</ENAME>
<SALARY>10000</SALARY>
<EMPADDR>
<STREET>300 Embarcadero</STREET>
<CITY>Palo Alto</CITY>
<STATE>CA</STATE>
<ZIP>94056</ZIP>
</EMPADDR>
</EMPLIST_ITEM>
<!-- additional employee types within the employee list -->
</EMPLIST>
</ROW>
<!-- additional rows ... -->
</ROWSET>
As in the last example, the mapping is canonical, that is, <ROWSET> contains <ROW> elements that contain elements corresponding to the columns. As before, the elements corresponding to scalar type columns simply contain the data from the column.
Things get more complex with elements corresponding to a complex type column. For example, <DEPTADDR> corresponds to the DEPTADDR column which is of object type ADDRESS. Consequently, <DEPTADDR> contains sub-elements corresponding to the attributes specified in the type ADDRESS. These sub-elements can contain data or sub-elements of their own, again depending if the attribute they correspond to is of a simple or complex type.
When dealing with elements corresponding to database collections, things are also different. Specifically, the <EMPLIST> element corresponds to the EMPLIST column which is of a EmployeeListType collection type. Consequently, the <EMPLIST> element contains a list of <EMPLIST_ITEM> elements, each corresponding to one of the elements of the collection.
Other observations to make about the preceding mapping are:
The <ROW> elements contain a cardinality attribute num.
If a particular column or attribute value is NULL, then for that row, the corresponding XML element is left out altogether.
If a top level scalar column name starts with the at sign (@) character, then the particular column is mapped to an XML attribute instead of an XML element.
Often, you need to generate XML with a specific structure. Since the desired structure may differ from the default structure of the generated XML document, you want to have some flexibility in this process. You can customize the structure of a generated XML document using one of the following methods:
Source customizations are done by altering the query or database schema. The simplest and most powerful source customizations include the following:
In the database schema, create an object-relational view that maps to the desired XML document structure.
In your query:
Use cursor subqueries, or cast-multiset constructs to get nesting in the XML document that comes from a flat schema.
Alias column and attribute names to get the desired XML element names.
Alias top level scalar type columns with identifiers that begin with the at sign (@) to have them map to an XML attribute instead of an XML element. For example, select empno as "@empno",... from emp, results in an XML document where the <ROW> element has an attribute EMPNO.
XML SQL Utility enables you to modify the mapping it uses to transform SQL data into XML. You can make any of the following SQL to XML mapping changes:
Change or omit the <ROWSET> tag.
Change or omit the <ROW> tag.
Change or omit the attribute num. This is the cardinality attribute of the <ROW> element.
Specify the case for the generated XML element names.
Specify that XML elements corresponding to elements of a collection must have a cardinality attribute.
Specify the format for dates in the XML document.
Specify that null values in the XML document have to be indicated using a nullness attribute, rather then by omission of the element.
XML to SQL mapping is just the reverse of the SQL to XML mapping.
Consider the following differences when mapping from XML to SQL, compared to mapping from SQL to XML:
When going from XML to SQL, the XML attributes are ignored. Thus, there is really no mapping of XML attributes to SQL.
When going from SQL to XML, mapping is performed from the ResultSet created by the SQL query to XML. This way the query can span multiple database tables or views. What is formed is a single ResultSet that is then converted into XML. This is not the case when going from XML to SQL, where:
To insert one XML document into multiple tables or views, you must create an object-relational view over the target schema.
If the view is not updatable, one solution is to use INSTEAD-OF-INSERT triggers.
If the XML document does not perfectly map into the target database schema, there are three things you can do:
Modify the Target. Create an object-relational view over the target schema, and make the view the new target.
Modify the XML Document. Use XSLT to transform the XML document. The XSLT can be registered with XSU so that the incoming XML is automatically transformed, before any mapping attempts are made.
Modify XSU's XML-to-SQL Mapping. You can instruct XSU to perform case insensitive matching of the XML elements to database columns or attributes.
You can tell XSU to use the name of the element corresponding to a database row instead of ROW.
You can specify in XSU the date format to use when parsing dates in the XML document.
This section describes how XSU works when performing the following tasks:
XSU generation is simple. SQL queries are executed and the ResultSet is retrieved from the database. Metadata about the ResultSet is acquired and analyzed. Using the mapping described in "Default SQL-to-XML Mapping" , the SQL result set is processed and converted into an XML document.
There are certain types of queries that XSU cannot handle, especially those that mix columns of type LONG or LONG RAW with CURSOR() expressions in the Select clause. Please note that LONG and LONG RAW are two examples of datatypes that JDBC accesses as streams and whose use is deprecated. If you migrate these columns to CLOBs, then the queries will succeed.
To insert the contents of an XML document into a particular table or view, XSU first retrieves the metadata about the target table or view. Based on the metadata, XSU generates a SQL INSERT statement. XSU extracts the data out of the XML document and binds it to the appropriate columns or attributes. Finally the statement is executed.
For example, assume that the target table is dept1 and the XML document is the one generated from dept1.
XSU generates the following INSERT statement.
INSERT INTO dept1 (deptno, deptname, deptaddr, emplist) VALUES (?,?,?,?)
Next, the XSU parses the XML document, and for each record, it binds the appropriate values to the appropriate columns or attributes:
deptno <- 100
deptname <- SPORTS
deptaddr <- AddressType('100 Redwood Shores Pkwy','Redwood Shores',
'CA','94065')
emplist <- EmployeeListType(EmployeeType(7369,'John',100000,
AddressType('300 Embarcadero','Palo Alto','CA','94056'),...)
The statement is then executed. Insert processing can be optimized to insert in batches, and commit in batches.
Updates and deletes differ from inserts in that they can affect more than one row in the database table. For inserts, each ROW element of the XML document can affect at most one row in the table, if there are no triggers or constraints on the table.
However, with both updates and deletes, the XML element can match more than one row if the matching columns are not key columns in the table. For updates, you must provide a list of key columns that XSU needs to identify the row to update. For example, to update the DEPTNAME to SportsDept instead of Sports, you can have an XML document such as:
<ROWSET>
<ROW num="1">
<DEPTNO>100</DEPTNO>
<DEPTNAME>SportsDept</DEPTNAME>
</ROW>
</ROWSET>
and supply the DEPTNO as the key column. This results in the following UPDATE statement:
UPDATE dept1 SET deptname = ? WHERE deptno = ?
and bind the values this way:
deptno <- 100 deptname <- SportsDept
For updates, you can also choose to update only a set of columns and not all the elements present in the XML document.
For deletes, you can choose to give a set of key columns for the delete to identify the rows. If the set of key columns are not given, then the DELETE statement tries to match all the columns given in the document. For an XML document:
<ROWSET>
<ROW num="1">
<DEPTNO>100</DEPTNO>
<DEPTNAME>Sports</DEPTNAME>
<DEPTADDR>
<STREET>100 Redwood Shores Pkwy</STREET>
<CITY>Redwood Shores</CITY>
<STATE>CA</STATE>
<ZIP>94065</ZIP>
</DEPTADDR>
</ROW>
<!-- additional rows ... -->
</ROWSET>
To delete, XSU builds a DELETE statement (one for each ROW element):
DELETE FROM dept1 WHERE deptno = ? AND deptname = ? AND deptaddr = ?
The binding is:
deptno <- 100
deptname <- sports
deptaddr <- addresstype('100 redwood shores pkwy','redwood city','ca',
'94065')
XSU comes with a simple command line front end that gives you quick access to XML generation and insertion.
The XSU command-line options are provided through the Java class, OracleXML. Invoke it by calling:
java OracleXML
This prints the front end usage information. To run the XSU command-line front end, first specify where the executable is located. Add the following to your CLASSPATH:
Also, since XSU depends on Oracle XML Parser and JDBC drivers, make the location of these components known. To do this, the CLASSPATH must include the locations of:
Oracle XML Parser Java library (xmlparserv2.jar)
JDBC library (classes12.jar if using xsu12.jar or classes111.jar if using xsu111.jar)
A JAR file for XMLType.
For XSU generation capabilities, use the XSU getXML parameter. For example, to generate an XML document by querying the employees table in the hr schema, use:
java OracleXML getXML -user "hr/hr" "select * from employees"
This performs the following tasks:
Connects to the current default database
Executes the query select * from employees
Converts the result to XML
Displays the result
The getXML parameter supports a wide range of options. They are explained in the following section.
Table 7-1 lists the OracleXML getXML options:
Table 7-1 XSU's OracleXML getXML Options
| getXML Option | Description |
|---|---|
-user username/password |
Specifies the username and password to connect to the database. If this is not specified, the user defaults to scott/tiger. Note that the connect string is also being specified. The username and password can be specified as part of the connect string. |
-conn JDBC_connect_string |
Specifies the JDBC database connect string. By default the connect string is: "jdbc:oracle:oci:@"): |
-withDTD |
Instructs the XSU to generate the DTD along with the XML document. |
-withSchema |
Instructs the XSU to generate the schema along with the XML document. |
-rowsetTag tag_name |
Specifies rowset tag (the tag that encloses all the XML elements corresponding to the records returned by the query). The default rowset tag is ROWSET. Specifying an empty string for the rowset tells the XSU to completely omit the rowset element. |
-rowTag tag_name |
Specifies the row tag (the tag used to enclose the data corresponding to a database row). The default row tag is ROW. Specifying an empty string for the row tag tells the XSU to completely omit the row tag. |
-rowIdAttr row_id_attribute_name |
Names the attribute of the ROW element keeping track of the cardinality of the rows. By default this attribute is called num. Specifying an empty string ("") as the rowID attribute will tell the XSU to omit the attribute. |
-rowIdColumn row_Id_column_name |
Specifies that the value of one of the scalar columns from the query is to be used as the value of the rowID attribute. |
-collectionIdAttr collection_id_attribute name |
Names the attribute of an XML list element keeping track of the cardinality of the elements of the list (the generated XML lists correspond to either a cursor query, or collection). Specifying an empty string ("") as the rowID attribute will tell the XSU to omit the attribute. |
-useNullAttrId |
Tells the XSU to use the attribute NULL (TRUE/FALSE) to indicate the nullness of an element. |
-styleSheet stylesheet_URI |
Specifies the stylesheet in the XML PI (Processing Instruction). |
-stylesheetType stylesheet_type |
Specifies the stylesheet type in the XML PI (Processing Instruction). |
-errorTag error tag_name |
Specifies the error tag - the tag to enclose error messages that are formatted into XML. |
-raiseNoRowsException |
Tells the XSU to raise an exception if no rows are returned. |
-maxRows maximum_rows |
Specifies the maximum number of rows to be retrieved and converted to XML. |
-skipRows number_of_rows_to_skip |
Specifies the number of rows to be skipped. |
-encoding encoding_name |
Specifies the character set encoding of the generated XML. |
-dateFormat date_format |
Specifies the date format for the date values in the XML document. |
-fileName SQL_query_fileName
| |
Specifies the file name that contains the query, or specify the query itself. |
-useTypeForCollElemTag |
Use type name for column-element tag (by default XSU uses the column-name_item. |
-setXSLTRef URI |
Set the XSLT external entity reference. |
-useLowerCase
| - |
Generate lowercase or uppercase tag names, respectively. The default is to match the case of the SQL object names from which the tags are generated. |
-withEscaping |
There are characters that are legal in SQL object names but illegal in XML tags. This option means that if such a character is encountered, it is escaped rather than throwing an exception. |
-raiseException |
By default the XSU catches any error and produces the XML error. This changes this behavior so the XSU actually throws the raised Java exception. |
To insert an XML document into the employees table in the hr schema, use the following syntax:
java OracleXML putXML -user "hr/hr" -fileName "/tmp/temp.xml" "employees"
This performs the following tasks:
Connects to the current database
Reads the XML document from the given file
Parses it, matches the tags with column names
Inserts the values appropriately into the employees table
|
Note: The XSU command line front end,putXML, currently only publishes XSU insert functionality. |
Table 7-2 lists the putXML options:
Table 7-2 XSU's OracleXML putXML Options
| putXML Options | Description |
|---|---|
-user username/password |
Specifies the username and password to connect to the database. If this is not specified, the user defaults to scott/tiger. The connect string is also being specified; the username and password can be specified as part of the connect string. |
-conn JDBC_connect_string |
Specifies the JDBC database connect string. By default the connect string is: "jdbc:oracle:oci:@"): |
-batchSize batching_size |
Specifies the batch size, that controls the number of rows that are batched together and inserted in a single trip to the database to improve performance. |
-commitBatch commit_size |
Specifies the number of inserted records after which a commit is to be executed. Note that if the autocommit is TRUE (the default), then setting the commitBatch has no consequence. |
-rowTag tag_name |
Specifies the row tag (the tag used to enclose the data corresponding to a database row). The default row tag is ROW. Specifying an empty string for the row tag tells XSU that no row-enclosing tag is used in the XML document. |
-dateFormat date_format |
Specifies the date format for the date values in the XML document. |
-ignoreCase |
Makes the matching of the column names with tag names case insensitive (for example, "EmpNo" will match with "EMPNO" if ignoreCase is on). |
-fileName file_name |
Specifies the XML document to insert, a local file. |
-URL URL |
Specifies a URL to fetch the document from. |
-xmlDoc xml_document |
Specifies the XML document as a string on the command line. |
-tableName table |
The name of the table to put the values into. |
-withEscaping |
If SQL to XML name escaping was used when generating the doc, then this will turn on the reverse mapping. |
-setXSLTURI |
XSLT to apply to the XML document before inserting. |
-setXSLTRef URI |
Set the XSLT external entity reference. |
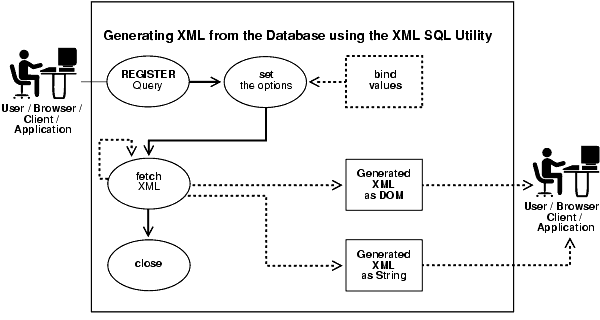
The OracleXMLQuery class makes up the XML generation part of the XSU Java API. Figure 7-4 illustrates the basic steps you need to take when using OracleXMLQuery to generate XML:
Create a connection.
Create an OracleXMLQuery instance by supplying an SQL string or a ResultSet object.
Obtain the result as a DOM tree or XML string.
Figure 7-4 Generating XML With XML SQL Utility for Java: Basic Steps
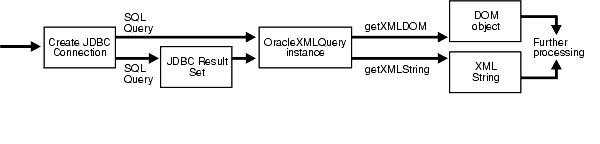
The following examples illustrate how XSU can generate an XML document in its DOM or string representation given a SQL query. See Figure 7-5.
1. Create a connection
Before generating the XML you must create a connection to the database. The connection can be obtained by supplying the JDBC connect string. First register the Oracle JDBC class and then create the connection, as follows
// import the Oracle driver..
import oracle.jdbc.*;
// Load the Oracle JDBC driver
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
// Create the connection.
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@","hr","hr");
Here, we use the default connection for the JDBC OCI driver. You can connect to the scott schema supplying the password tiger.
You can also use the JDBC thin driver to connect to the database. The thin driver is written in pure Java and can be called from within applets or any other Java program.
Here is an example of connecting using the JDBC thin driver:
// Create the connection.
Connection conn =
DriverManager.getConnection("jdbc:oracle:thin:@dlsun489:1521:ORCL",
"hr","hr");
The thin driver requires you to specify the host name (dlsun489), port number (1521), and the Oracle SID (ORCL), which identifies a specific Oracle instance on the machine.
No connection is needed when run in the server. When writing server side Java code, that is, when writing code that will run in the server, you need not establish a connection using a username and password, since the server-side internal driver runs within a default session. You are already connected. In this case call the defaultConnection() on the oracle.jdbc.driver.OracleDriver() class to get the current connection, as follows:
import oracle.jdbc.*; // Load the Oracle JDBC driver DriverManager.registerDriver(new oracle.jdbc.OracleDriver()); Connection conn = new oracle.jdbc.OracleDriver().defaultConnection ();
The remaining discussion either assumes you are using an OCI connection from the client or that you already have a connection object created. Use the appropriate connection creation based on your needs.
2. Creating an OracleXMLQuery Class instance:
Once you have registered your connection, create an OracleXMLQuery class instance by supplying a SQL query to execute as follows:
// import the query class in to your class import oracle.xml.sql.query.OracleXMLQuery; OracleXMLQuery qry = new OracleXMLQuery (conn, "select * from employees");
You are now ready to use the query class.
3. Obtain the result as a DOM tree or XML string:
DOM object output. If, instead of a string, you wanted a DOM object, you can simply request a DOM output as follows:
org.w3c.DOM.Document domDoc = qry.getXMLDOM();
and use the DOM traversals.
XML string output. You can get an XML string for the result by:
String xmlString = qry.getXMLString();
Here is a complete listing of the program to extract (generate) the XML string. This program gets the string and prints it out to standard output:
import oracle.jdbc.*;
import oracle.xml.sql.query.OracleXMLQuery;
import java.lang.*;
import java.sql.*;
// class to test the String generation!
class testXMLSQL {
public static void main(String[] argv)
{
try{
// create the connection
Connection conn = getConnection("hr","hr");
// Create the query class.
OracleXMLQuery qry = new OracleXMLQuery(conn, "select * from employees");
// Get the XML string
String str = qry.getXMLString();
// Print the XML output
System.out.println(" The XML output is:\n"+str);
// Always close the query to get rid of any resources..
qry.close();
}catch(SQLException e){
System.out.println(e.toString());
}
}
// Get the connection given the user name and password..!
private static Connection getConnection(String username, String password)
throws SQLException
{
// register the JDBC driver..
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
// Create the connection using the OCI driver
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@",username,password);
return conn;
}
}
To run this program:
Store the code in a file called testXMLSQL.java
Compile it using javac, the Java compiler
Execute it by specifying: java testXMLSQL
You must have the CLASSPATH pointing to this directory for the Java executable to find the class. Alternatively use various visual Java tools including Oracle JDeveloper to compile and run this program. When run, this program prints out the XML file to the screen.
DOM represents an XML document in a parsed tree-like form. Each XML entity becomes a DOM node. Thus XML elements and attributes become DOM nodes while their children become child nodes. To generate a DOM tree from the XML generated by XSU, you can directly request a DOM document from XSU, as it saves the overhead of having to create a string representation of the XML document and then parse it to generate the DOM tree.
XSU calls the parser to directly construct the DOM tree from the data values. The following example illustrates how to generate a DOM tree. The example steps through the DOM tree and prints all the nodes one by one.
import org.w3c.dom.*;
import oracle.xml.parser.v2.*;
import java.sql.*;
import oracle.xml.sql.query.OracleXMLQuery;
import java.io.*;
class domTest{
public static void main(String[] argv)
{
try{
// create the connection
Connection conn = getConnection("hr","hr");
// Create the query class.
OracleXMLQuery qry = new OracleXMLQuery(conn, "select * from employees");
// Get the XML DOM object. The actual type is the Oracle Parser's DOM
// representation. (XMLDocument)
XMLDocument domDoc = (XMLDocument)qry.getXMLDOM();
// Print the XML output directly from the DOM
domDoc.print(System.out);
// If you instead want to print it to a string buffer you can do this.
StringWriter s = new StringWriter(10000);
domDoc.print(new PrintWriter(s));
System.out.println(" The string version ---> "+s.toString());
qry.close(); // Allways close the query!!
}catch(Exception e){
System.out.println(e.toString());
}
}
// Get the connection given the user name and password..!
private static Connection getConnection(String user, String passwd)
throws SQLException
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@",user,passwd);
return conn;
}
}
In the examples shown so far, XML SQL Utility (XSU) takes the ResultSet or the query, and generates the whole document from all the rows of the query. To obtain 100 rows at a time, you then have to fire off different queries to get the first 100 rows, the next 100, and so on. Also it is not possible to skip the first five rows of the query and then generate the result.
To obtain those results, use the XSU skipRows and maxRows parameter settings:
skipRows parameter, when set, forces the generation to skip the desired number of rows before starting to generate the result.
maxRows limits the number of rows converted to XML.
For example, if you set skipRows to a value of 5 and maxRows to a value of 10, then XSU skips the first 5 rows, then generates XML for the next 10 rows.
In Web scenarios, you may want to keep the query object open for the duration of the user's session. For example, consider the case of a Web search engine that gives the results of a user's search in a paginated fashion. The first page lists 10 results, the next page lists 10 more results, and so on.
To achieve this, request XSU to convert 10 rows at a time and keep the ResultSet state active, so that the next time you ask XSU for more results, it starts generating from the place the last generation finished.
There is also the case when the number of rows, or number of columns in a row are very large. In this case, you can generate multiple documents each of a smaller size. These cases can be handled by using the maxRows parameter and the keepObjectOpen function.
Typically, as soon as all results are generated, OracleXMLQuery internally closes the ResultSet, if it created one using the SQL query string given, since it assumes you no longer want any more results. However, in the case described earlier, to maintain that state, you need to call the keepObjectOpen function to keep the cursor active. See the following example.
This example shows how you can use the XSU for Java API to generate an XML page:
import oracle.sql.*;
import oracle.jdbc.*;
import oracle.xml.sql.*;
import oracle.xml.sql.query.*;
import oracle.xml.sql.dataset.*;
import oracle.xml.sql.docgen.*;
import java.sql.*;
import java.io.*;
public class b
{
public static void main(String[] args) throws Exception
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection conn =
DriverManager.getConnection"jdbc:oracle:oci:@", "hr", "hr"();
Statement stmt =
conn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,
ResultSet.CONCUR_READ_ONLY);
String sCmd = "SELECT FIRST_NAME, LAST_NAME FROM HR.EMPLOYEES";
ResultSet rs = stmt.executeQuery(sCmd);
OracleXMLQuery xmlQry = new OracleXMLQuery(conn, rs);
xmlQry.keepObjectOpen(true);
//xmlQry.setRowIdAttrName("");
xmlQry.setRowsetTag("ROWSET");
xmlQry.setRowTag("ROW");
xmlQry.setMaxRows(20);
//rs.beforeFirst();
String sXML = xmlQry.getXMLString();
System.out.println(sXML);
}
}
You saw how you can supply a SQL query and get the results as XML. In the last example, you retrieved paginated results. However in Web cases, you may want to retrieve the previous page and not just the next page of results. To provide this scrollable functionality, you can use the Scrollable ResultSet. Use the ResultSet object to move back and forth within the result set and use XSU to generate the XML each time. The following example illustrates how to do this.
This example shows you how to use the JDBC ResultSet to generate XML. Note that using the ResultSet might be necessary in cases that are not handled directly by XSU, for example, when setting the batch size, binding values, and so on. This example extends the previously defined pageTest class to handle any page.
public class pageTest
{
Connection conn;
OracleXMLQuery qry;
Statement stmt;
ResultSet rset;
int lastRow = 0;
public pageTest(String sqlQuery)
{
try{
conn = getConnection("hr","hr");
stmt = conn.createStatement();// create a scrollable Rset
ResultSet rset = stmt.executeQuery(sqlQuery); // get the result set.
qry = new OracleXMLQuery(conn,rset); // create an OracleXMLQuery
// instance
qry.keepCursorState(true); // Don't lose state after the first fetch
qry.setRaiseNoRowsException(true);
qry.setRaiseException(true);
}
catch (Exception e )
{
e.printStackTrace(System.out);
}
}
// Get the connection given the user name and password..!
private static Connection getConnection(String user, String passwd)
throws SQLException
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@",user,passwd);
return conn;
}
// Returns the next XML page..!
public String getResult(int startRow, int endRow)
{
qry.setMaxRows(endRow-startRow); // set the max # of rows to retrieve..!
return qry.getXMLString();
}
// Function to still perform the next page.
public String nextPage()
{
String result = getResult(lastRow,lastRow+10);
lastRow+= 10;
return result;
}
public void close() throws SQLException
{
stmt.close(); // close the statement..
conn.close(); // close the connection
qry.close(); // close the query..
}
public static void main(String[] argv)
{
String str;
try{
pageTest test = new pageTest("select * from employees");
int i = 0;
// Get the data one page at a time..!!!!!
while ((str = test.getResult(i,i+10))!= null)
{
System.out.println(str);
i+= 10;
}
test.close();
}
catch (Exception e )
{
e.printStackTrace(System.out);
}
}
}
The OracleXMLQuery class provides XML conversion only for query strings or ResultSets. But in your application if you have PL/SQL procedures that return REF cursors, how do you do the conversion?
In this case, you can use the earlier-mentioned ResultSet conversion mechanism to perform the task. REF cursors are references to cursor objects in PL/SQL. These cursor objects are valid SQL statements that can be iterated upon to get a set of values. These REF cursors are converted into OracleResultSet objects in the Java world.
You can execute these procedures, get the OracleResultSet object, and then send that to the OracleXMLQuery object to get the desired XML.
Consider the following PL/SQL function that defines a REF cursor and returns it:
CREATE OR REPLACE PACKAGE BODY testRef IS
function testRefCur RETURN empREF is
a empREF;
begin
OPEN a FOR select * from hr.employees;
return a;
end;
end;
/
Every time this function is called, it opens a cursor object for the query, select * from employees and returns that cursor instance. To convert this to XML, you do the following:
import org.w3c.dom.*;
import oracle.xml.parser.v2.*;
import java.sql.*;
import oracle.jdbc.*;
import oracle.xml.sql.query.OracleXMLQuery;
import java.io.*;
public class REFCURtest
{
public static void main(String[] argv)
throws SQLException
{
String str;
Connection conn = getConnection("hr","hr"); // create connection
// Create a ResultSet object by calling the PL/SQL function
CallableStatement stmt =
conn.prepareCall("begin ? := testRef.testRefCur(); end;");
stmt.registerOutParameter(1,OracleTypes.CURSOR); // set the define type
stmt.execute(); // Execute the statement.
ResultSet rset = (ResultSet)stmt.getObject(1); // Get the ResultSet
OracleXMLQuery qry = new OracleXMLQuery(conn,rset); // prepare Query class
qry.setRaiseNoRowsException(true);
qry.setRaiseException(true);
qry.keepCursorState(true); // set options (keep the cursor active.
while ((str = qry.getXMLString())!= null)
System.out.println(str);
qry.close(); // close the query..!
// Note since we supplied the statement and resultset, closing the
// OracleXMLquery instance will not close these. We need to
// explicitly close this ourselves..!
stmt.close();
conn.close();
}
// Get the connection given the user name and password..!
private static Connection getConnection(String user, String passwd)
throws SQLException
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@",user,passwd);
return conn;
}
}
To apply the stylesheet, on the other hand, use the applyStylesheet() command. This forces the stylesheet to be applied before generating the output.
When there are no rows to process, XSU simply returns a null string. However, it might be desirable to get an exception every time there are no more rows present, so that the application can process this through exception handlers. When the setRaiseNoRowsException() is set, then whenever there are no rows to generate for the output XSU raises an oracle.xml.sql.OracleXMLSQLNoRowsException. This is a runtime exception and need not be caught unless needed.
The following code extends the previous examples to use the exception instead of checking for null strings:
public class pageTest {
.... // rest of the class definitions....
public static void main(String[] argv)
{
pageTest test = new pageTest("select * from employees");
test.qry.setRaiseNoRowsException(true); // ask it to generate exceptions
try
{
while(true)
System.out.println(test.nextPage());
}
catch(oracle.xml.sql.OracleXMLSQLNoRowsException e)
{
System.out.println(" END OF OUTPUT ");
try{
test.close();
}
catch ( Exception ae )
{
ae.printStackTrace(System.out);
}
}
}
}
|
Note: Notice how the condition to check the termination changed from checking if the result isNULL to an exception handler. |
Now that you have seen how queries can be converted to XML, here is how you can put the XML back into the tables or views using XSU. The class oracle.xml.sql.dml.OracleXMLSave provides this functionality. It has methods to insert XML into tables, update existing tables with the XML document, and delete rows from the table based on XML element values.
In all these cases the given XML document is parsed, and the elements are examined to match tag names to column names in the target table or view. The elements are converted to the SQL types and then bound to the appropriate statement. The process for storing XML using XSU is shown in Figure 7-6.
Consider an XML document that contains a list of ROW elements, each of which constitutes a separate DML operation, namely, INSERT, UPDATE, or DELETE on the table or view.
To insert a document into a table or view, simply supply the table or the view name and then the document. XSU parses the document (if a string is given) and then creates an INSERT statement into which it binds all the values. By default, XSU inserts values into all the columns of the table or view and an absent element is treated as a NULL value. The following example shows you how the XML document generated from the employees table, can be stored in the table with relative ease.
This example inserts XML values into all columns:
// This program takes as an argument the file name, or a url to
// a properly formated XML document and inserts it into the HR.EMPLOYEES table.
import java.sql.*;
import oracle.xml.sql.dml.OracleXMLSave;
public class testInsert
{
public static void main(String argv[])
throws SQLException
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@","hr","hr");
OracleXMLSave sav = new OracleXMLSave(conn, "employees");
sav.insertXML(sav.getURL(argv[0]));
sav.close();
}
}
An INSERT statement of the form:
INSERT INTO hr.employees (employee_id, last_name, job_id, manager_id,
hire_date, salary, department_id) VALUES(?,?,?,?,?,?,?);
is generated, and the element tags in the input XML document matching the column names are matched and their values bound.
If you store the following XML document:
<?xml version='1.0'?>
<ROWSET>
<ROW num="1">
<EMPLOYEE_ID>7369</EMPLOYEE_ID>
<LAST_NAME>Smith</LAST_NAME>
<JOB_ID>CLERK</JOB_ID>
<MANAGER_ID>7902</MANAGER_ID>
<HIRE_DATE>12/17/1980 0:0:0</HIRE_DATE>
<SALARY>800</SALARY>
<DEPARTMENT_ID>20</DEPARTMENT_ID>
</ROW>
<!-- additional rows ... -->
</ROWSET>
to a file and specify the file to the program described earlier, you get a new row in the employees table containing the values 7369, Smith, CLERK, 7902, 12/17/1980,800,20 for the values named. Any element absent inside the row element is taken as a NULL value.
In certain cases, you may not want to insert values into all columns. This may be true when the group of values that you are getting is not the complete set and you need triggers or default values to be used for the rest of the columns. The code following shows how this can be done.
Assume that you are getting the values only for the employee number, name, and job and that the salary, manager, department number, and hire date fields are filled in automatically. First create a list of column names that you want the INSERT statement to work on and then pass it to the OracleXMLSave instance.
import java.sql.*;
import oracle.xml.sql.dml.OracleXMLSave;
public class testInsert
{
public static void main(String argv[])
throws SQLException
{
Connection conn = getConnection("hr","hr");
OracleXMLSave sav = new OracleXMLSave(conn, "hr.employees");
String [] colNames = new String[3];
colNames[0] = "EMPLOYEE_ID";
colNames[1] = "LAST_NAME";
colNames[2] = "JOB_ID";
sav.setUpdateColumnList(colNames); // set the columns to update..!
// Assume that the user passes in this document as the first argument!
sav.insertXML(sav.getURL(argv[0]));
sav.close();
}
// Get the connection given the user name and password..!
private static Connection getConnection(String user, String passwd)
throws SQLException
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@",user,passwd);
return conn;
}
}
An INSERT statement is generated
INSERT INTO hr.employees (employee_id, last_name, job_id) VALUES (?, ?, ?);
In the preceding example, if the inserted document contains values for the other columns (HIRE_DATE, and so on), those are ignored. Also an insert operation is performed for each ROW element that is present in the input. These inserts are batched by default.
Now that you know how to insert values into the table from XML documents, see how you can update only certain values. In an XML document, to update the salary of an employee and the department that they work in:
<ROWSET>
<ROW num="1">
<EMPLOYEE_ID>7369</EMPLOYEE_ID>
<SALARY>1800</SALARY>
<DEPARTMENT_ID>30</DEPARTMENT_ID>
</ROW>
<ROW>
<EMPLOYEE_ID>2290</EMPLOYEE_ID>
<SALARY>2000</SALARY>
<HIRE_DATE>12/31/1992</HIRE_DATE>
<!-- additional rows ... -->
</ROWSET>
You can use the XSU to update the values. For updates, you must supply XSU with the list of key column names. These form part of the WHERE clause in the UPDATE statement. In the employees table shown earlier, employee number (employee_id) column forms the key. Use this for updates.
This example updates table, emp, using keyColumns:
import java.sql.*;
import oracle.xml.sql.dml.OracleXMLSave;
public class testUpdate
{
public static void main(String argv[])
throws SQLException
{
Connection conn = getConnection("hr","hr");
OracleXMLSave sav = new OracleXMLSave(conn, "hr.employees");
String [] keyColNames = new String[1];
keyColNames[0] = "EMPLOYEE_ID";
sav.setKeyColumnList(keyColNames);
// Assume that the user passes in this document as the first argument!
sav.updateXML(sav.getURL(argv[0]));
sav.close();
}
// Get the connection given the user name and password..!
private static Connection getConnection(String user, String passwd)
throws SQLException
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@",user,passwd);
return conn;
}
}
In this example, two UPDATE statements are generated. For the first ROW element, you generate an UPDATE statement to update the SALARY and HIRE_DATE fields as follows:
UPDATE hr.employees SET salary = 2000 AND hire_date = 12/31/1992 WHERE employee_id = 2290;
For the second ROW element:
UPDATE hr.employees SET salary = 2000 AND hire_date = 12/31/1992 WHERE employee_id = 2290;
You may want to specify a list of columns to update. This speeds the processing since the same UPDATE statement can be used for all the ROW elements. Also you can ignore other tags in the XML document.
|
Note: When you specify a list of columns to update, if an element corresponding to one of the update columns is absent, it will be treated asNULL. |
If you know that all the elements to be updated are the same for all the ROW elements in the XML document, you can use the setUpdateColumnNames() function to set the list of columns to update.
import java.sql.*;
import oracle.xml.sql.dml.OracleXMLSave;
public class testUpdate
{
public static void main(String argv[])
throws SQLException
{
Connection conn = getConnection("hr","hr");
OracleXMLSave sav = new OracleXMLSave(conn, "hr.employees");
String [] keyColNames = new String[1];
keyColNames[0] = "EMPLOYEE_ID";
sav.setKeyColumnList(keyColNames);
// you create the list of columns to update..!
// Note that if you do not supply this, then for each ROW element in the
// XML document, you would generate a new update statement to update all
// the tag values (other than the key columns)present in that element.
String[] updateColNames = new String[2];
updateColNames[0] = "SALARY";
updateColNames[1] = "JOB_ID";
sav.setUpdateColumnList(updateColNames); // set the columns to update..!
// Assume that the user passes in this document as the first argument!
sav.updateXML(sav.getURL(argv[0]));
sav.close();
}
// Get the connection given the user name and password..!
private static Connection getConnection(String user, String passwd)
throws SQLException
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@",user,passwd);
return conn;
}
}
When deleting from XML documents, you can set the list of key columns. These columns are used in the WHERE clause of the DELETE statement. If the key column names are not supplied, then a new DELETE statement is created for each ROW element of the XML document, where the list of columns in the WHERE clause of the DELETE statement will match those in the ROW element.
Consider this delete example:
import java.sql.*;
import oracle.xml.sql.dml.OracleXMLSave;
public class testDelete
{
public static void main(String argv[])
throws SQLException
{
Connection conn = getConnection("hr","hr");
OracleXMLSave sav = new OracleXMLSave(conn, "hr.employees");
// Assume that the user passes in this document as the first argument!
sav.deleteXML(sav.getURL(argv[0]));
sav.close();
}
// Get the connection given the user name and password..!
private static Connection getConnection(String user, String passwd)
throws SQLException
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@",user,passwd);
return conn;
}
}
Using the same XML document shown previously for the update example, you get two DELETE statements:
DELETE FROM hr.employees WHERE employee_id=7369 AND salary=1800 AND department_id=30; DELETE FROM hr.employees WHERE employee_id=2200 AND salary=2000 AND hire_date=12/31/1992;
The DELETE statements were formed based on the tag names present in each ROW element in the XML document.
If instead, you want the DELETE statement to only use the key values as predicates, you can use the setKeyColumn function to set this.
import java.sql.*;
import oracle.xml.sql.dml.OracleXMLSave;
public class testDelete
{
public static void main(String argv[])
throws SQLException
{
Connection conn = getConnection("hr","hr");
OracleXMLSave sav = new OracleXMLSave(conn, "hr.employees");
String [] keyColNames = new String[1];
keyColNames[0] = "EMPLOYEE_ID";
sav.setKeyColumnList(keyColNames);
// Assume that the user passes in this document as the first argument!
sav.deleteXML(sav.getURL(argv[0]));
sav.close();
}
// Get the connection given the user name and password..!
private static Connection getConnection(String user, String passwd)
throws SQLException
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@",user,passwd);
return conn;
}
}
Here is the single generated DELETE statement:
DELETE FROM hr.employees WHERE employee_id=?
Here is more information about XSU.
Exceptions are discussed.
XSU catches all exceptions that occur during processing and throws an oracle.xml.sql.OracleXMLSQLException which is a runtime exception. The calling program thus does not have to catch this exception all the time, if the program can still catch this exception and do the appropriate action. The exception class provides functions to get the error message and also get the parent exception, if any. For example, the program shown later, catches the run time exception and then gets the parent exception.
This exception is generated when the setRaiseNoRowsException is set in the OracleXMLQuery class during generation. This is a subclass of the OracleXMLSQLException class and can be used as an indicator of the end of row processing during generation.
import java.sql.*;
import oracle.xml.sql.query.OracleXMLQuery;
public class testException
{
public static void main(String argv[])
throws SQLException
{
Connection conn = getConnection("hr","hr");
// wrong query this will generate an exception
OracleXMLQuery qry = new OracleXMLQuery(conn, "select * from employees
where sd = 322323");
qry.setRaiseException(true); // ask it to raise exceptions..!
try{
String str = qry.getXMLString();
}catch(oracle.xml.sql.OracleXMLSQLException e)
{
// Get the original exception
Exception parent = e.getParentException();
if (parent instanceof java.sql.SQLException)
{
// perform some other stuff. Here you simply print it out..
System.out.println(" Caught SQL Exception:"+parent.getMessage());
}
else
System.out.println(" Exception caught..!"+e.getMessage());
}
}
// Get the connection given the user name and password..!
private static Connection getConnection(String user, String passwd)
throws SQLException
{
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection conn =
DriverManager.getConnection("jdbc:oracle:oci:@",user,passwd);
return conn;
}
}
This section lists XSU hints.
If you have the following XML in your customer.xml file:
<ROWSET>
<ROW num="1">
<CUSTOMER>
<CUSTOMERID>1044</CUSTOMERID>
<FIRSTNAME>Paul</FIRSTNAME>
<LASTNAME>Astoria</LASTNAME>
<HOMEADDRESS>
<STREET>123 Cherry Lane</STREET>
<CITY>SF</CITY>
<STATE>CA</STATE>
<ZIP>94132</ZIP>
</HOMEADDRESS>
</CUSTOMER>
</ROW>
</ROWSET>
what database schema structure can you use to store this XML with XSU?
Since your example is more than one level deep (that is, it has a nested structure), you can use an object-relational schema. The XML preceding will canonically map to such a schema. An appropriate database schema is:
CREATE TYPE address_type AS OBJECT ( street VARCHAR2(40), city VARCHAR2(20), state VARCHAR2(10), zip VARCHAR2(10) ); / CREATE TYPE customer_type AS OBJECT ( customerid NUMBER(10), firstname VARCHAR2(20), lastname VARCHAR2(20), homeaddress address_type ); / CREATE TABLE customer_tab ( customer customer_type);
In case you wanted to load customer.xml by means of XSU into a relational schema, you can still do it by creating objects in views on top of your relational schema.
For example, you can have a relational table that contains all the following information:
CREATE TABLE cust_tab ( customerid NUMBER(10), firstname VARCHAR2(20), lastname VARCHAR2(20), street VARCHAR2(40), city VARCHAR2(20), state VARCHAR2(20), zip VARCHAR2(20) );
Then, you create a customer view that contains a customer object on top of it, as in the following example:
CREATE VIEW customer_view AS SELECT customer_type(customerid, firstname, lastname, address_type(street,city,state,zip)) customer FROM cust_tab;
Finally, you can flatten your XML using XSLT and then insert it directly into your relational schema. However, this is the least recommended option.
Currently the XML SQL Utility (XSU) can only store data in a single table. It maps a canonical representation of an XML document into any table or view. But there is a way to store XML with XSU across tables. You can do this using XSLT to transform any document into multiple documents and insert them separately. Another way is to define views over multiple tables (using object views if needed) and then do the insertions into the view. If the view is inherently non-updatable (because of complex joins), then you can use INSTEAD OF triggers over the views to do the inserts.
You have to use XSLT to transform your XML document; that is, you must change the attributes into elements. XSU does assume canonical mapping from XML to a database schema. This takes away a bit from the flexibility, forcing you to sometimes resort to XSLT, but at the same time, in the common case, it does not burden you with having to specify a mapping.
By default, XSU is case sensitive. You have two options: use the correct case or use the ignoreCase feature.
Due to a number of shortcomings of the DTD, this functionality is not available. The W3C XML Schema recommendation is finalized, but this functionality is not available yet in XSU.
An example of an JDBC thin driver connect string is:
jdbc:oracle:thin:user/password@hostname:portnumber:DBSID;
Furthermore, the database must have an active TCP/IP listener. A valid OCI connect string is:
jdbc:oracle:oci:user/password@hostname
Does XML SQL Utility commit after it is done inserting, deleting, or updating? What happens if an error occurs?
By default the XSU executes a number of INSERT, DELETE, or UPDATE statements at a time. The number of statements batch together and executed at the same time can be overridden using the setBatchSize feature.
Also, by default XSU does no explicit commits. If AUTOCOMMIT is on (default for the JDBC connection), then after each batch of statement executions a commit occurs. You can override this by turning AUTOCOMMIT off and then specifying after how many statement executions a commit occurs, which can be done using the setCommitBatch feature.
If an error occurs, XSU rolls back to either the state the target table was in before the particular call to XSU, or the state right after the last commit made during the current call to XSU.
From XSU release 2.1.0 you can map a particular column or a group of columns to an XML attribute instead of an XML element. To achieve this, you have to create an alias for the column name, and prepend the at sign (@) before the name of this alias. For example:
* Create a file called select.sql with the following content :
SELECT empno "@EMPNO", ename, job, hiredate
FROM emp
ORDER BY empno
* Call the XML SQL Utility :
java OracleXML getXML -user "scott/tiger" \
-conn "jdbc:oracle:thin:@myhost:1521:ORCL" \
-fileName "select.sql"
* As a result, the XML document will look like :
<?xml version = '1.0'?>
<ROWSET>
<ROW num="1" EMPNO="7369">
<ENAME>SMITH</ENAME>
<JOB>CLERK</JOB>
<HIREDATE>12/17/1980 0:0:0</HIREDATE>
</ROW>
<ROW num="2" EMPNO="7499">
<ENAME>ALLEN</ENAME>
<JOB>SALESMAN</JOB>
<HIREDATE>2/20/1981 0:0:0</HIREDATE>
</ROW>
</ROWSET>
|
Note: All attributes must appear before any non-attribute. |
Since the XML document is created in a streamed manner, the following query:
SELECT ename, empno "@EMPNO", ...
does not generate the expected result. It is currently not possible to load XML data stored in attributes. You will still need to use an XSLT transformation to change the attributes into elements. XSU assumes canonical mapping from XML to a database schema.
|
 Copyright © 2001, 2003 Oracle Corporation All Rights Reserved. |
|