Release 2 (9.2)
Part Number A96656-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Java Developer's Guide Release 2 (9.2) Part Number A96656-01 |
|
You can increase your Java application performance through one of the following methods:
The Java language was designed for a platform-independent, secure development model. To accomplish these goals, some execution performance was sacrificed. Translating Java bytecodes into machine instructions degrades performance. To regain some of the performance loss, you may choose to natively compile certain classes. For example, you may decide to natively compile code with CPU intensive classes.
Without native compilation, the Java code you load to the server is interpreted, and the underlying core classes upon which your code relies (java.lang.*) are natively compiled.
Native compilation provides a speed increase ranging from two to ten times the speed of the bytecode interpretation. The exact speed increase is dependent on several factors, including:
Because Java bytecodes were designed to be compact, natively compiled code can be considerably larger than the original bytecode. However, because the native code is stored in a shared library, it is shared among all users of the database.
Most JVMs use Just-In-Time compilers that convert the Java bytecodes to native machine instructions when methods are invoked. The Accelerator uses an Ahead-Of-Time approach to recompiling the Java classes.
This static compilation approach provides a large, consistent performance gain, regardless of the number of users or the code paths they traverse on the server. After compilation, the tool loads the statically compiled libraries into Oracle9i, which are then shared between users, processes, and sessions.
Most Ahead-Of-Time native compilers compile directly into a platform-dependent language. For portability requirements, this was not feasible. Figure 6-1 illustrates how the Accelerator translates the Java classes into a version of C that is platform-independent. The C code is compiled and linked to supply the final platform-dependent, natively compiled shared libraries or DLLs.
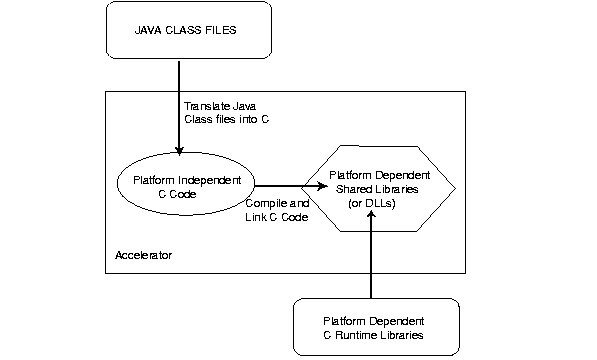
Given a JAR file, the Accelerator performs the following:
The Accelerator translates, compiles, and links the retrieved classes on the client. For this reason, you must natively compile on the intended platform environment to which this application will be deployed. The result is a single deployment JAR file for all classes within the project.
$ORACLE_HOME/javavm/admin directory.
All core Java class libraries and Oracle-provided Java code within Oracle9i is natively compiled for greater execution speed. Java classes exist as shared libraries in $ORACLE_HOME/javavm/admin, where each shared library corresponds to a Java package. For example, orajox8java_lang.so on Solaris and orajox8java_lang.dll on Windows NT hold java.lang classes. Specifics of packaging and naming can vary by platform. The Oracle9i JVM uses natively compiled Java files internally and opens them, as necessary, at runtime.
The Accelerator can be used by Java application products that need performance increased and are deployed in Oracle9i. The Accelerator command-line tool, ncomp, natively compiles your code and loads it in Oracle9i. However, in order to use ncomp, you must first provide some initial setup.
You must install the following before invoking Accelerator:
ncomp.System*.properties file located in the $ORACLE_HOME/javavm/jahome directory. Since the compiler and linker information is platform-specific, the configuration for these items is detailed in the README for your platform.ncomp the following role and security permissions:
|
Note: DBA role contains both the |
JAVA_DEPLOY: The user must be assigned to the JAVA_DEPLOY role in order to be able to deploy the shared libraries on the server, which both the ncomp and deploync utilities perform. For example, the role is assigned to DAVE, as follows:
SQL> GRANT JAVA_DEPLOY TO DAVE;
FilePermission: Accelerator stores the shared libraries with the natively compiled code on the server. In order for Accelerator to store these libraries, the user must be granted FilePermission for read and write access to directories and files under $ORACLE_HOME on the server. One method for granting FilePermission for all desired directories is to grant the user the JAVASYSPRIV role, as follows:
SQL> GRANT JAVASYSPRIV TO DAVE;
See the Security chapter in the Oracle9i Java Developer's Guide for more information JAVASYSPRIV and granting FilePermission.
The following sections show how to do basic native compilation using Accelerator.
All the Java classes contained within a JAR file must already be loaded within the database. Execute the ncomp tool to instruct Accelerator to natively compile all these classes. The following code natively compiles all classes within the pubProject.JAR file:
ncomp -user scott/tiger pubProject.JAR
If you change any of the classes within this JAR file, Accelerator recompiles the shared library for the package that contains the changed classes. It will not recompile all shared libraries. However, if you want all classes within a JAR file to be recompiled--regardless of whether they were previously natively compiled--execute ncomp with the -force option, as follows:
ncomp -user scott/tiger -force pubProject.JAR
Accelerator, implemented within the ncomp tool, natively compiles all classes within the specified JAR, ZIP, or list of classes. Accelerator natively compiles these classes and places them into shared libraries according to their package. Note that these classes must first be loaded into the database.
If the classes are designated within a JAR file and have already been loaded in the database, you can natively compile your Java classes by executing the following:
ncomp -user SCOTT/TIGER myClasses.jar
There are options that allow you control over how the details of native compilation are handled.
ncomp [ options ] <class_designation_file>
-user | -u <username>/<password>[@<database_url>]
[-load]
[-projectDir | -d <project_directory>]
[-force]
[-lightweightDeployment]
[-noDeploy]
[-outputJarFile | -o <jar_filename>]
[-thin]
[-oci | -oci8]
[-update]
[-verbose]
|
Note: These options are demonstrated within the scenarios described in "Native Compilation Usage Scenarios". |
Table 6-1 summarizes the ncomp arguments. The <class_designation_file> can be a <file>.jar, <file>.zip, or <file>.classes.
| Argument | Description and Values |
|---|---|
|
|
The full pathname and filename of a JAR file that contains the classes that are to be natively compiled. If you are executing in the directory where the JAR file exists and you do not specify the - |
|
|
The full pathname and filename of a ZIP file that contains the classes that are to be natively compiled. If you are executing in the directory where the ZIP file exists and you do not specify the - |
|
|
The full pathname and filename of a classes file, which contains the list of classes to be natively compiled. If you are executing in the directory where the classes file exists and you do not specify the -projectDir option, you may give only the name of the classes file. See "Natively Compiling Specific Classes" for a description of a classes file. |
|
|
Specifies a user, password, and database connect string; the files will be loaded into this database instance. The argument has the form |
|
|
The native compilation is performed on all classes. Previously compiled classes are not passed over. |
|
|
Provides an option for deploying shared libraries and native compilation information separately. This is useful if you need to preserve resources when deploying. See "lightweightDeployment" for more information. |
|
|
Executes |
|
|
All natively compiled classes output into a deployment JAR file. This option specifies the name of the deployment JAR file and its destination directory. If omitted, the |
|
|
Specifies that the native compilation results only in the output deployment JAR file, which is not deployed to the server. The resulting deployment JAR can be deployed to any server using the deploync tool. |
|
|
The database URL that is provided on the - |
|
|
The database URL that is provided on the -user option uses an OCI URL address for the database URL syntax. However, if neither - |
|
|
Specifies the full path for the project directory. If not specified, Accelerator uses the directory from which |
|
|
If you add more classes to a < |
|
|
Output native compilation text with detail. |
The permissible forms of @<database> depend on whether you specify -oci or -thin; -oci is the default.
-oci: @<database> is optional; if you do not specify, then ncomp uses the user's default database. If specified, then <database> can be a TNS name or a Oracle Net Services name-value list.-thin: @<database> is required. The format is <host>:<lport>:<SID>.
Accelerator places compilation information and the compiled shared libraries in one JAR file, copies the shared libraries to $ORACLE_HOME/javavm/admin directory on the server, and deploys the compilation information to the server. If you want to place the shared libraries on the server yourself, you can do so through the lightweightDeployment option. The lightweightDeployment option enables you to do your deployment in two stages:
noDeploy and -lightweightDeployment options. This creates an deployment JAR file with only ncomp information, such as transitive closure information. The shared libraries are not saved within the deployment JAR file. Thus, the deployment JAR file is much smaller.Any errors that occur during native compilation are printed to the screen. Any errors that occur during deployment of your shared libraries to the server or during runtime can be viewed with the statusnc tool or by referring to the JACCELERATOR$DLL_ERRORS table.
If an error is caught while natively compiling the designated classes, Accelerator denotes these errors, abandons work on the current package, and continues its compilation task on the next package. The native compilation continues for the rest of the packages. The package with the class that contained the error will not be natively compiled at all.
After fixing the problem with the class, you can choose to do one of the following:
If you choose not to recompile the classes, but to load the correct Java class into the database instead, then the corrected class and all classes that are included in the resolution validation for that class--whether located within the same shared library or a different shared library--will be executed in interpreted mode. That is, the JVM will not run these classes natively. All the other natively compiled classes will continue to execute in native format. When you execute the statusnc command on the reloaded class or any of its referred classes, they will have an NEED_NCOMPING status message.
Possible errors for a Java class:
Possible errors for deployment of native compilation JAR file:
The following scenarios demonstrate how you can use each of the options for the ncomp tool can be used:
If all classes are loaded into the database and you have completed your testing of the application, you can request Accelerator to natively compile the tested classes. Accelerator takes in a JAR, ZIP, or list of classes to determine the packages and classes to be included in the native compilation. The Accelerator then retrieves all of the designated classes from the server and natively compiles them into shared libraries--each library containing a single package of classes.
Assuming that the classes have already been loaded within the server, you execute the following command to natively compile all classes listed within a class designation file, such as the pubProject.jar file, as follows:
ncomp -user SCOTT/TIGER pubProject.jar
If you change any of the classes within the class designation file and ask for recompilation, Accelerator recompiles only the packages that contain the changed classes. It will not recompile all packages.
Once you have tested the designated classes, you may wish to natively compile them on a host other than the test machine. Once you transfer the designated class file to this platform, the classes in this file must be loaded into the database before native compilation can occur. The following loads the classes through loadjava and then executes native compilation for the class designation file--pubProject.jar:
ncomp -user SCOTT/TIGER@dbhost:5521:orcl -thin -load pubProject.jar
If you want all classes within a class designation file to be recompiled--regardless of whether they were previously natively compiled--execute ncomp with the -force option. You might want to use the -force option to ensure that all classes are compiled, resulting in a deployment JAR file that can be deployed to other Oracle9i databases. You can specify the native compilation deployment JAR file with the -outputJarFile option. The following forces a recompilation of all Java classes within the class designation file--pubProject.jar--and creates a deployment JAR file with the name of pubworks.jar:
ncomp -user SCOTT/TIGER -force -outputJarFile pubworks.jar pubProject.jar
The deployment JAR file contains the shared libraries for your classes, and installation classes specified to these shared libraries. It does not contain the original Java classes. To deploy the natively compiled deployment JAR file to any Oracle9i (of the appropriate platform type), you must do the following:
pubProject.jar file would be loaded into the database using the loadjava tool.By default, the Accelerator uses the directory where ncomp is executed as its build environment. The Accelerator downloads several class files into this directory and then uses this directory for the compilation and linking process.
If you do not want to have Accelerator put any of its files into the current directory, create a working directory, and specify this working directory as the project directory with the -projectDir option. The following directs Accelerator to use /tmp/jaccel/pubComped as the build directory. This directory must exist before specifying it within the -projectDir option. Accelerator will not create this directory for you.
ncomp -user SCOTT/TIGER -projectDir /tmp/jaccel/pubComped pubProject.jar
You can specify one or more classes that are to be natively compiled, within a text-based <file>.classes file. Use the following Java syntax to specify packages and/or individual classes within this file:
import COM.myDomain.myPackage.*; import COM.myDomain.myPackage.mySubPackage.*;
import COM.myDomain.myPackage.myClass;
Once explicitly listed, specify the name and location of this class designation file on the command line. Given the following pubworks.classes file:
import COM.myDomain.myPackage.*; import COM.myDomain.hisPackage.hisSubPackage.*; import COM.myDomain.herPackage.herClass; import COM.myDomain.petPackage.petClass;
The following directs Accelerator to compile all classes designated within this file: all classes in myPackage, hisSubPackage and the individual classes, herClass and myClass. These classes must have already been loaded into the database:
ncomp -user SCOTT/TIGER /tmp/jaccel/pubComped/pubworks.classes
If you change any of the classes within this JAR file, Accelerator will only recompile shared libraries that contain the changed classes. It will not recompile all shared libraries designated in the JAR file. However, if you want all classes within a JAR file to be recompiled--regardless of whether they were previously natively compiled--you execute ncomp with the -force option, as follows:
ncomp -user scott/tiger -force pubProject.JAR
You can deploy any deployment JAR file with the deploync command. This includes the default output JAR file, <file>_depl.jar or the JAR created when you used the ncomp -outputJarFile option. The operating system and Oracle9i database version must be the same as the platform where it was natively compiled.
|
Note: The list of shared libraries deployed into Oracle9i are listed within the JACCELERATOR$DLLS table. |
deploync [options] <deployment>.jar
-user | -u <username>/<password>[@<database_url>]
[-projectDir | -d <project_directory>]
[-thin]
[-oci | -oci8]
Table 6-2 summarizes the deploync arguments.
Deploy the natively compiled deployment JAR file pub.jar to the dbhost database as follows:
deploync -user SCOTT/TIGER@dbhost:5521:orcl -thin /tmp/jaccel/PubComped/pub.jar
After the native compilation is completed, you can check the status for your Java classes through the statusnc command. This tool will print out--either to the screen or to a designated file--the status of each class. In addition, the statusnc tool always saves the output within the JACCELERATOR$STATUS table. The values can be the following:
statusnc [ options ] <class_designation_file>
-user <user>/<password>[@database]
[-output | -o <filename>]
[-projectDir | -d <directory>]
[-thin]
[-oci | -oci8]
Table 6-3 summarizes the statusnc arguments. The <class_designation_file> can be a <file>.jar, <file>.zip, or <file>.classes.
| Argument | Description |
|---|---|
|
|
The full pathname and filename of a JAR file that was natively compiled. |
|
|
The full pathname and filename of a ZIP file that was natively compiled. |
|
|
The full pathname and filename of a classes file, which contains the list of classes that was natively compiled. See "Natively Compiling Specific Classes" for a description of a classes file. |
|
|
Specifies a user, password, and database connect string where the files are loaded. The argument has the form |
|
|
Designates that the |
|
|
Specifies the full path for the project directory. If not specified, Accelerator uses the directory from which |
|
|
The database URL that is provided on the - |
|
|
The database URL that is provided on the - |
statusnc -user SCOTT/TIGER -output pubStatus.txt /tmp/jaccel/PubComped/pub.jar
The typical and custom database installation process furnishes a database that has been configured for reasonable Java usage during development. However, runtime use of Java should be determined by the usage of system resources for a given deployed application. Resources you use during development can vary widely, depending on your activity. The following sections describe how you can configure memory, how to tell how much SGA memory you are using, and what errors denote a Java memory issue:
You can modify the following database initialization parameters to tune your memory usage to reflect more accurately your application needs:
SHARED_POOL_SIZE--Shared pool memory is used by the class loader within the JVM. The class loader uses an average of about 8 KB for each loaded class. Shared pool memory is used when loading and resolving classes into the database. It is also used when compiling source in the database or when using Java resource objects in the database.
The memory specified in SHARED_POOL_SIZE is consumed transiently when you use loadjava. The database initialization process (executing initjvm.sql against a clean database, as opposed to the installed seed database) requires SHARED_POOL_SIZE to be set to 50 MB as it loads the Java binaries for approximately 8,000 classes and resolves them. The SHARED_POOL_SIZE resource is also consumed when you create call specifications and as the system tracks dynamically loaded Java classes at runtime.
JAVA_POOL_SIZE--The Oracle9i JVM memory manager allocates all other Java state during runtime execution from the amount of memory allocated using JAVA_POOL_SIZE. This memory includes the shared in-memory representation of Java method and class definitions, as well as the Java objects migrated to session space at end-of-call. In the first case, you will be sharing the memory cost with all Java users. In the second case, in a shared server, you must adjust JAVA_POOL_SIZE allocation based on the actual amount of state held in static variables for each session. See "Java Pool Memory" for more information on JAVA_POOL_SIZE.JAVA_SOFT_SESSIONSPACE_LIMIT--This parameter allows you to specify a soft limit on Java memory usage in a session, which will warn you if you must increase your Java memory limits. Every time memory is allocated, the total memory allocated is checked against this limit.
When a user's session-duration Java state exceeds this size, Oracle9i JVM generates a warning that is written into the trace files. While this warning is simply an informational message and has no impact on your application, you should understand and manage the memory requirements of your deployed classes, especially as they relate to usage of session space.
JAVA_MAX_SESSIONSPACE_SIZE--If a user-invokable Java program executing in the server can be used in a way that is not self-limiting in its memory usage, this setting may be useful to place a hard limit on the amount of session space made available to it. The default is 4 GB. This limit is purposely set extremely high to be normally invisible.
When a user's session-duration Java state attempts to exceeds this size, your application can receive an out-of-memory failure.
Oracle9i's unique memory management facilities and sharing of read-only artifacts (such as bytecodes) enables HelloWorld to execute with a per-session incremental memory requirement of only 35 KB. More stateful server applications have a per-session incremental memory requirement of approximately 200 KB. Such applications must retain a significant amount of state in static variables across multiple calls. Refer to the discussion in the "End-of-Call Migration" section for more information on understanding and controlling migration of static variables at end-of-call.
You can set the defaults for JAVA_POOL_SIZE and SHARED_POOL_SIZE in the database installation template. The Database Configuration Assistant (DBCA) allows you to modify these values within the Memory section, as shown below in Figure 6-2.
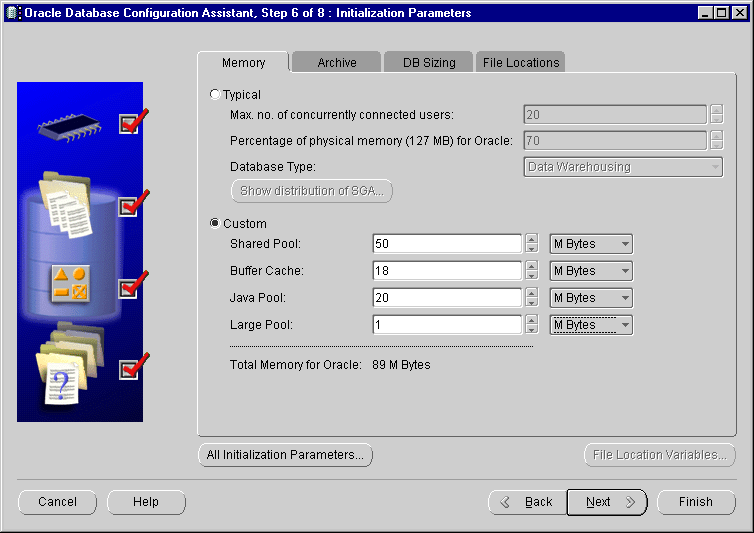
Text description of the illustration dbca_poo.gif
Java pool memory is used in server memory for all session-specific Java code and data within the JVM. Java pool memory is used in different ways, depending on what mode the Oracle9i server is running in.
The following is what constitutes the Java pool memory used within a dedicated server:
This includes readonly memory, such as code vectors, and methods. In total, this can average about 4 KB-8 KB for each class.
For a dedicated server, this is stored in UGA within the PGA--not within the SGA.
Under dedicated servers, the total required Java pool memory depends on the applications running and may range between 10 and 50 MB.
The following is what constitutes the Java pool memory used within a shared server:
This includes readonly memory, such as vectors, and methods. In total, this can average about 4 KB-8 KB for each class.
Because Java pool memory size is fixed, you must estimate the total requirement for your applications and multiply by the number of concurrent sessions the applications want to create to calculate the total amount of necessary Java pool memory. Each UGA grows and shrinks as necessary; however, all UGAs combined must be able to fit within the entire fixed Java pool space.
Under shared servers, this figure could be large. Java-intensive, multi-user benchmarks could require more than 100 MB.
|
Note: If you are compiling code on the server, rather than compiling on the client and loading to the server, you might need a bigger JAVA_POOL_SIZE than the default 20 MB. |
You can find out how much of Java pool memory is being used by viewing the V$SGASTAT table. Its rows include pool, name, and bytes. Specifically, the last two rows show the amount of Java pool memory used and how much is free. The total of these two items equals the number of bytes that you configured in the database initialization file.
SVRMGR> select * from v$sgastat; POOL NAME BYTES ----------- -------------------------- ---------- fixed_sga 69424 db_block_buffers 2048000 log_buffer 524288 shared pool free memory 22887532 shared pool miscellaneous 559420 shared pool character set object 64080 shared pool State objects 98504 shared pool message pool freequeue 231152 shared pool PL/SQL DIANA 2275264 shared pool db_files 72496 shared pool session heap 59492 shared pool joxlod: init P 7108 shared pool PLS non-lib hp 2096 shared pool joxlod: in ehe 4367524 shared pool VIRTUAL CIRCUITS 162576 shared pool joxlod: in phe 2726452 shared pool long op statistics array 44000 shared pool table definiti 160 shared pool KGK heap 4372 shared pool table columns 148336 shared pool db_block_hash_buckets 48792 shared pool dictionary cache 1948756 shared pool fixed allocation callback 320 shared pool SYSTEM PARAMETERS 63392 shared pool joxlod: init s 7020 shared pool KQLS heap 1570992 shared pool library cache 6201988 shared pool trigger inform 32876 shared pool sql area 7015432 shared pool sessions 211200 shared pool KGFF heap 1320 shared pool joxs heap init 4248 shared pool PL/SQL MPCODE 405388 shared pool event statistics per sess 339200 shared pool db_block_buffers 136000java pool free memory 30261248java pool memory in use 1974272037 rows selected.
The two common memory errors that can occur are as follows:
If you run out of memory while compiling (within loadjava), you will see the following error:
A SQL exception occurred while compiling: : ORA-04031: unable to allocate bytes of shared memory ("shared pool","unknown object","joxlod: init h", "JOX: ioc_ allocate_pal")
The solution is to shut down your database and reset JAVA_POOL_SIZE to a larger value. The mention of "shared pool" in the error message is a misleading reference to running out of memory in the "Shared Global Area". It does not mean that you should increase your SHARED_POOL_SIZE. Instead, you must increase your JAVA_POOL_SIZE, restart your server, and try again.
If you run out of memory while loading classes, it can fail silently, leaving invalid classes in the database. Later, if you try to invoke or resolve any invalid classes, you will see ClassNotFoundException or NoClassDefFoundException exceptions being thrown at runtime. You would get the same exceptions if you were to load corrupted class files. You should perform the following:
loadjava -force option to force the new class being loaded to replace the class already resident in the server.loadjava -resolve option to attempt resolution of a class during the load process. This allows you to catch missing classes at load time, not run time.select * from user_objects where object_name = dbms_java.shortname('');
The STATUS field should be "VALID". If loadjava complains about memory problems or failures such as "connection lost", increase SHARED_POOL_SIZE and JAVA_POOL_SIZE, and try again.
Oracle9i preserves the state of your Java program between calls by migrating all objects that are reachable from static variables into session space at the end of the call. Session space exists within the client's session to store static variables and objects that exist between calls. Oracle9i JVM performs this migration operation at the end of every call, without any intervention by you.
This migration operation is a memory and performance consideration; thus, you should be aware of what you designate to exist between calls, and keep the static variables and objects to a minimum. If you store objects in static variables needlessly, you impose an unnecessary burden on the memory manager to perform the migration and consume per-session resources. By limiting your static variables to only what is necessary, you help the memory manager and improve your server's performance.
To maximize the number of users who can execute your Java program at the same time, it is important to minimize the footprint of a session. In particular, to achieve maximum scalability, an inactive session should take up as little memory space as possible. A simple technique to minimize footprint is to release large data structures at the end of every call. You can lazily recreate many data structures when you need them again in another call. For this reason, the Oracle9i JVM has a mechanism for calling a specified Java method when a session is about to become inactive, such as at end-of-call time.
This mechanism is the EndOfCallRegistry notification. It enables you to clear static variables at the end of the call and reinitialize the variables using a lazy initialization technique when the next call comes in. You should execute this only if you are concerned about the amount of storage you require the memory manager to store in between calls. It becomes a concern only for more complex stateful server applications you implement in Java.
The decision of whether to null-out data structures at end-of-call and then recreate them for each new call is a typical time and space trade-off. There is some extra time spent in recreating the structure, but you can save significant space by not holding on to the structure between calls. In addition, there is a time consideration, because objects--especially large objects--are more expensive to access after they have been migrated to session space. The penalty results from the differences in representation of session, as opposed to call-space based objects.
Examples of data structures that are candidates for this type of optimization include:
You can register the static variables that you want cleared at the end of the call when the buffer, field, or data structure is created. Within the Oracle-specified oracle.aurora.memoryManager.EndOfCallRegistry class, the registerCallback method takes in an object that implements a Callback object. The registerCallback object stores this object until the end of the call. When end-of-call occurs, Oracle9i JVM invokes the act method within all registered Callback objects. The act method within the Callback object is implemented to clear the user-defined buffer, field, or data structure. Once cleared, the Callback is removed from the registry.
|
Note: If the end of the call is also the end of the session, callbacks are not invoked, because the session space will be cleared anyway. |
The way that you use the EndOfCallRegistry depends on whether you are dealing with objects held in static fields or instance fields.
EndOfCallRegistry to clear state associated with an entire class. In this case, the Callback object should be held in a private static field. Any code that requires access to the cached data that was dropped between calls must invoke a method that lazily creates--or recreates--the cached data. The example below does the following:
Callback object within a static field, thunk.Callback object for end-of-call migration.Callback.act method to free up all static variables, including the Callback object itself.createCachedField, for lazily recreating the cache.When the user creates the cache, the Callback object is automatically registered within the getCachedField method. At end-of-call, Oracle9i JVM invokes the registered Callback.act method, which frees the static memory.
import oracle.aurora.memoryManager.Callback; import oracle.aurora.memoryManager.EndOfCallRegistry; class Example { static Object cachedField = null;private static Callback thunk = null;static void clearCachedField() { // clear out both the cached field, and the thunk so they don't // take up session space between calls cachedField = null; thunk = null; } private static Object getCachedField() { if (cachedField == null) { // save thunk in static field so it doesn't get reclaimed // by garbage collectorthunk = new Callback () {public void act(Object obj) {Example.clearCachedField();}}; // register thunk to clear cachedField at end-of-call.EndOfCallRegistry.registerCallback(thunk);// finally, set cached field cachedField = createCachedField(); } return cachedField; } private static Object createCachedField() { .... } }
EndOfCallRegistry to clear state in data structures held in instance fields. For example, when a state is associated with each instance of a class, each instance has a field that holds the cached state for the instance and fills in the cached field as necessary. You can access the cached field with a method that ensures the state is cached.
Callback object.Callback.act method to free up the instance's fields.Callback object registers itself for end-of-call migration.createCachedField, for lazily recreating the cache.When the user creates the cache, the Callback object is automatically registered within the getCachedField method. At end-of-call, Oracle9i JVM invokes the registered Callback.act method, which frees the cache.
This approach ensures that the lifetime of the Callback object is identical to the lifetime of the instance, because they are the same object.
import oracle.aurora.memoryManager.Callback; import oracle.aurora.memoryManager.EndOfCallRegistry; class Example2implementsCallback { private Object cachedField = null; public voidact(Object obj) { // clear cached field cachedField = null; obj = null; } // our accessor method private static Object getCachedField() { if (cachedField == null) { // if cachedField is not filled in then we need to // register self, and fill it in.EndOfCallRegistry.registerCallback(self);cachedField = createCachedField(); } return cachedField; } private Object createCachedField() { .... } }
A weak table holds the registry of end-of-call callbacks. If either the Callback object or value are not reachable (see JLS section 12.6) from the Java program, both object and value will be dropped from the table. The use of a weak table to hold callbacks also means that registering a callback will not prevent the garbage collector from reclaiming that object. Therefore, you must hold on to the callback yourself if you need it--you cannot rely on the table holding it back.
You can find other ways in which end-of-call notification will be useful to your applications. The following sections give the details for methods within the EndOfCallRegistry class and the Callback interface:
The registerCallback method installs a Callback object within a registry. At the end of the call, Oracle9i JVM invokes the act methods of all registered Callback objects.
You can register your Callback object by itself or with a value object. If you need additional information stored within an object to be passed into act, you can register this object within the value parameter.
public static void registerCallback(Callback thunk, Object value); public static void registerCallback(Callback thunk);
static void runCallbacks()
The JVM calls this method at end-of-call and calls act for every Callback object registered using registerCallback. You should never call this method in your code. It is called at end-of-call, before object migration and before the last finalization step.
Interface oracle.aurora.memoryManager.Callback
Any object you want to register using EndOfCallRegistry.registerCallback implements the Callback interface. This interface can be useful in your application, where you require notification at end-of-call.
public void act(Object value)
You can implement any activity that you require to occur at the end of the call. Normally, this method will contain procedures for clearing any memory that would be saved to session space.
The purpose of the Memory Profiling Utility (MemStat) is to trace, profile, and report on the allocated memory that is accessible through static variables in your Oracle9i Java program. You can then use the information in this report to locate and eliminate unnecessary static data in your Java classes, thereby reducing the static footprint of your Java program and improving the performance of repeated Java calls into the database.
The Oracle9i JVM uses three kinds of memory:
Java language semantics specify that static variables persist across calls. At the end of each call, the Oracle9i JVM copies the call memory that is accessible through the static variables in each class into session memory so that it can be saved and restored on subsequent calls to methods in those Java classes. If there is a lot of static data or a complex graph of interconnected objects, then there is considerable overhead during the end-of-call processing while the JVM allocates session memory and copies the static data to it.
A typical technique for tuning object-oriented programs for faster performance is to eliminate the allocation of unnecessary objects from your program. For example, you can create a static instance of a commonly used object and reuse it rather than creating a new one every time you need it. However, the interactions among the different database memories complicate such techniques, and can require analysis of the speed trade-off for allocating dynamic objects versus the space trade-off for the end-of-call copying of static objects. If a static object is large, or if there are many such objects, or if there are many calls, then the speed advantage gained by caching the object may be lost, due to the traversal of the object graph during end-of-call processing.
Depending on how you invoke it, MemStat will analyze either a single class or all classes that are loaded into the current session. For each class, MemStat enumerates the static variables of the class. These variables are known as the roots. Depending on the structure of each variable, MemStat performs three different analyses:
This process is repeated recursively until all objects reachable from all static variables have been recorded. Because it is possible for large object graphs to contain cycles, MemStat also records any circular references it encounters during the analysis.
The purpose of MemStat is to analyze and report on the object graph that is accessible from the static variables in your program. You can invoke the analysis directly from any point in your program, and you can also register it to run at the end of a call.
Because there is no standard output mechanism for database calls, MemStat produces its report in the form of HTML files, in a directory that you specify. When the report is finished, you can view these files with any HTML-capable Web browser.
MemStat is implemented in three static methods on the class oracle.aurora.memstat.MemStat.
You can call it in three different ways:
The method call for reporting on a single class is:
MemStat.writeDump (Class MyClass, String outputPath, String filePrefix);
The method call for reporting on all loaded classes is:
MemStat.writeDump (String outputPath, String filePrefix);
The method call for reporting on all loaded classes at the end-of-call is:
MemStat.writeDumpAtEOC (String outputPath, String filePrefix);
The outputPath parameter represents the directory in which the MemStat reports are generated. The outputPath string must be in a file name format that is suitable to the platform on which the report is generated. For example, /home/base/memstat is suitable for a Solaris platform; the Windows format might be c:\\base\\memstat. Note that Java requires doubling of the backslashes inside a string, but not the forward slashes.
The filePrefix is the base file name for the HTML files that are generated in the outputPath directory. Because MemStat reports can be voluminous, and many Web browsers have limitations on the size of the files they can browse, MemStat breaks long reports into separate files. The filePrefix is the basis for all file names in a given report and is augmented by an incremental numeric suffix. If, for example, the test report produces three files, the main report file will be named test.htm, and additional report files will be named test1.htm and test2.htm.
If you call MemStat more than once in a given call, be careful to use different base names or different output directories, lest the subsequent reports overwrite the previous ones. For example, if you call MemStat before and after you perform some memory-consuming operation, naming the first report before and the second report after will prevent name collisions, while still writing the report files into the same directory. Using multiple directories is more complicated: you must remember to grant separate FilePermissions (see below) for each directory in which you want to write.
Here are some sample MemStat calls:
MemStat.writeDump (MyClass.class, "c:\\base\\memstat", "myclass"); MemStat.writeDump ("/home/base/memstat", "test"); MemStat.writeDumpAtEOC ("/home/base/memstat", "eoc");
MemStat requires certain permissions to be granted to the user or role under which it runs. Because MemStat runs in the Oracle server process, these permissions grant access to the resources that MemStat requires:
The following SQL statements grant these permissions to user JIM:
call dbms_java.grant_permission ('JIM',
'SYS:java.lang.reflect.ReflectPermission', 'suppressAccessChecks', null); call dbms_java.grant_permission ('JIM', 'SYS:oracle.aurora.security.JServerPermission', 'JRIExtensions', null); call dbms_java.grant_permission ('JIM', 'SYS:java.io.FilePermission', '/home/base/memstat', 'read,write'); // Solaris call dbms_java.grant_permission ('JIM', 'SYS:java.io.FilePermission', 'c:\base\memstat', 'read,write'); // Windows
If the Oracle Server is running on a Windows platform, the output file path named in the MemStat call is subtly different from the path in the SQL grant_permission call. In Java strings, you must use double backslashes; in SQL you need only one backslash.
This section describes the format of the MemStat report. You can browse the MemStat output report with any HTML-capable Web browser. To do this, point the browser at the base file name that is specified. For example, the following points the browser at the test.htm file:
c:\base\memstat\test.htm.
The report begins with a summary of the memory usage at the time MemStat is invoked. This summary should give you an overall idea of the amount of memory used by the Java call that you are analyzing.
Following the summary is a list of the unique classes that are traversed during the MemStat analysis. For every object found during the memory analysis, MemStat has recorded its class and its size in each of call, session, and permanent memory. The largest objects are sorted first, because eliminating these will yield the largest performance improvement. The list is actually sorted by the largest of these three sizes, calculated as max (call, max (session, permanent)). For each class, this table also shows how many bytes are occupied by objects of that class, how many objects there are, their minimum, maximum and average size, and for arrays, the standard deviation of the sizes.
Following the class summary is one or more tables describing each root object. The title of the object describes the package and class of the object. Each row of the table describes:
Following the root objects are the objects pointed to by the roots; the objects are separated by a dividing rule. One, two, or three tables describe each object:
The title for each object describes the memory in which the object resides: Call, Session, or Permanent. Each object is described by:
toString() method to the objectAn object that refers to another object is linked by an HTML link to the tables representing the object to which it refers. You can navigate the object graph using these links, as you would navigate hyperlinks in a text document.
The following shows an example of the output of the MemStat tool:
MemStat Results
2000-06-01 17:07:05.645
| Run-Time | Value |
|---|---|
|
Session Size |
143360 |
|
NewSpace Size |
262144 |
|
NewSpace Enabled |
true |
|
Intern Table Size |
261814 |
| Total Memory Allocation | Call | Session | Permanent |
|---|---|---|---|
|
Objects |
726 |
926 |
3217 |
|
Total Size |
54861 |
39348 |
127418 |
|
Minimum |
12 |
12 |
12 |
|
Maximum |
16396 |
2060 |
8076 |
|
Average |
75.6 |
42.5 |
39.6 |
|
Std Deviation |
679.2 |
93.7 |
233.7 |
|
 Copyright © 2000, 2002 Oracle Corporation. All Rights Reserved. |
|

