Release 2 (9.2)
Part Number A96519-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Backup and Recovery Concepts Release 2 (9.2) Part Number A96519-01 |
|
This chapter introduces concepts that are fundamental to backup and recovery. It is intended as a general overview. Subsequent chapters explore backup and recovery concepts in greater detail.
This chapter includes the following topics:
In general, backup and recovery refers to the various strategies and procedures involved in protecting your database against data loss and reconstructing the data should that loss occur. The reconstructing of data is achieved through media recovery, which refers to the various operations involved in restoring, rolling forward, and rolling back a backup of database files.
This section contains these topics:
A backup is a copy of data. This copy can include important parts of the database such as the control file and datafiles. A backup is a safeguard against unexpected data loss and application errors. If you lose the original data, then you can reconstruct it by using a backup.
Backups are divided into physical backups and logical backups. Physical backups, which are the primary concern in a backup and recovery strategy, are copies of physical database files. You can make physical backups with either the Recovery Manager (RMAN) utility or operating system utilities. In contrast, logical backups contain logical data (for example, tables and stored procedures) extracted with the Oracle Export utility and stored in a binary file. You can use logical backups to supplement physical backups.
To restore a physical backup of a datafile or control file is to reconstruct it and make it available to the Oracle database server. To recover a restored datafile is to update it by applying archived redo logs and online redo logs, that is, records of changes made to the database after the backup was taken. If you use RMAN, then you can also recover restored datafiles with incremental backups, which are backups of a datafile that contain only blocks that changed after a previous incremental backup.
After the necessary files are restored, media recovery must be initiated by the user. Media recovery can use both archived redo logs and online redo logs to recover the datafiles. If you use SQL*Plus, then you can run the RECOVER command to perform recovery. If you use RMAN, then you run the RMAN RECOVER command to perform recovery.
Figure 1-1 illustrates the basic principle of backing up, restoring, and performing media recovery on a database.
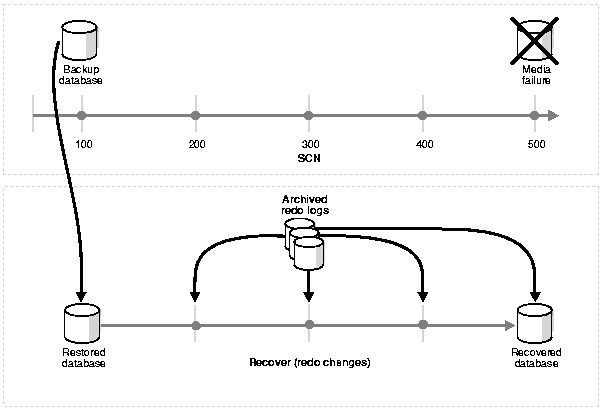
Unlike media recovery, Oracle performs crash recovery and instance recovery automatically after an instance failure. Crash and instance recovery recover a database to its transaction-consistent state just before instance failure. By definition, crash recovery is the recovery of a database in a single-instance configuration or an Oracle Real Application Clusters configuration in which all instances have crashed. In contrast, instance recovery is the recovery of one failed instance by a live instance in an Oracle Real Application Clusters configuration.
Crash and instance recovery involve two distinct operations: rolling forward the current, online datafiles by applying both committed and uncommitted transactions contained in online redo records, and then rolling back changes made in uncommitted transactions to their original state. Because crash and instance recovery are automatic, this manual will not discuss these operations.
See Also:
|
Several problems can halt the normal operation of an Oracle database or affect database I/O operations. The following sections describe the most common types of problems. For some of these problems, crash and instance recovery occur automatically and require no action on the part of the database administrator. For other problems, administrator-initiated media recovery is required.
This section contains these topics:
An error can occur when trying to write or read an file on disk that is required to operate an Oracle database. This occurrence is called media failure because there is a physical problem reading or writing to files on the storage medium.
A common example of media failure is a disk head crash that causes the loss of all database files on a disk drive. All files associated with a database are vulnerable to a disk crash, including datafiles, control files, online redo logs, and archived logs.
The appropriate recovery from a media failure depends on the files affected. Media failure is the primary concern of a backup and recovery strategy, because it typically requires restoring some or all database files and the application of redo during recovery.
See Also:
|
Media failures can affect one or all types of files necessary for the operation of an Oracle database, including datafiles, online redo log files, and control files. Also, media failures can affect archived redo logs stored on disk.
Database operation after a media failure of online redo log files or control files depends on whether the online redo log or control file is protected by multiplexing, as recommended. When an online redo log or control file is multiplexed, multiple copies of the file are maintained on the system. Typically, multiplexed files are stored on separate disks.
If a media failure damages a single disk, and if you have a multiplexed online redo log, then the database can usually continue to operate without significant interruption. Damage to a nonmultiplexed online redo log causes database operation to halt and may cause permanent loss of data. Damage to any control file, whether it is multiplexed or not, halts database operation once Oracle attempts to read or write to the damaged control file, which happens frequently, for example at every checkpoint and log switch.
Media failures that affect datafiles can be divided into two categories: read errors and write errors. In a read error, Oracle discovers it cannot read a datafile and an operating system error is returned to the application, along with an Oracle error indicating that the file cannot be found, cannot be opened, or cannot be read. Oracle continues to run, but the error is returned each time an unsuccessful read occurs. At the next checkpoint, a write error will occur when Oracle attempts to write the file header as part of the standard checkpoint process.
If Oracle discovers that it cannot write to a datafile, and if Oracle is in ARCHIVELOG mode, then Oracle returns an error in the database writer trace file and takes the datafile offline automatically. Only the datafile that cannot be written to is taken offline; the tablespace containing that file remains online.
If the datafile that cannot be written to is in the SYSTEM tablespace, then the file is not taken offline. Instead, an error is returned and Oracle shuts down the instance. The reason for this exception is that all files in the SYSTEM tablespace must be online in order for Oracle to operate properly. For the same reason, the undo tablespaces (if in automatic undo management mode) or the datafiles of a tablespace containing active rollback segments (if in manual undo management mode) must remain online.
If Oracle cannot write to a datafile, and Oracle is not archiving the filled online redo log files, then the database writer background process fails and the current instance fails. If the problem is temporary (for example, the disk controller was powered off), then crash or instance recovery usually can be performed using the online redo log files, in which case the instance can be restarted. However, if a datafile is permanently damaged and archiving is not used, then you must restore the entire database using the most recent consistent backup.
Recovery is not needed on any read-only tablespace during crash or instance recovery. During startup, recovery verifies that each online read-only datafile does not need media recovery. That is, the file was not restored from a backup taken before it was made read-only. If you restore a read-only tablespace from a backup taken before the tablespace was made read-only, then you cannot access the tablespace until you complete media recovery.
As an administrator, you can do little to prevent user errors such as accidentally dropping a table. Often, user error can be reduced by increased training on database and application principles. You can also avoid user errors by administering privileges correctly so that users are able to do less potential damage. Furthermore, by planning an effective recovery scheme ahead of time, you can ease the work necessary to recover from user errors.
Typically, a user error such as a dropped table requires either re-entering the lost changes manually (if a record of them exists), importing the dropped object (if an export file exists), or performing incomplete recovery either of an individual tablespaces (called tablespace point-in-time recovery (TSPITR)) or of the entire database.
Database instance failure occurs when a problem prevents an Oracle database instance from continuing to run. An instance failure can result from a hardware problem, such as a power outage, or a software problem, such as an operating system crash. Instance failure also results when you issue a SHUTDOWN ABORT or STARTUP FORCE statement.
When one or more instances fail, Oracle automatically recovers the lost changes associated with the instance or instances. Crash or instance recovery consists of the following steps:
DEAD and marking the rollback or undo segments containing these transactions as PARTLY AVAILABLE.See Also:
|
Statement failure occurs when there is a logical failure in the handling of a statement in an Oracle program. For example, assume that all extents of a table (in other words, the number of extents specified in the MAXEXTENTS parameter of the CREATE TABLE statement) are allocated, and are completely filled with data. A valid INSERT statement cannot insert a row because no space is available. Therefore, the statement fails.
If a statement failure occurs, then the Oracle software or operating system returns an error. A statement failure usually requires no recovery steps: Oracle automatically corrects for statement failure by rolling back any effects of the statement and returning control to the application. The user can simply execute the statement again after the problem indicated by the error message is corrected. For example, if insufficient extents are allocated, then the DBA needs to allocate more extents so that the user's statement can execute.
A process failure is a failure in a user, server, or background process of a database instance such as an abnormal disconnect or process termination. When a process failure occurs, the failed subordinate process cannot continue work, although the other processes of the database instance can continue.
The Oracle background process PMON detects aborted Oracle processes. If the aborted process is a user or server process, then PMON resolves the failure by rolling back the current transaction of the aborted process and releasing any resources that this process was using. Recovery of the failed user or server process is automatic. If the aborted process is a background process, then the instance usually cannot continue to function correctly. Therefore, you must shut down and restart the instance.
When your system uses networks such as local area networks and phone lines to connect client workstations to database servers, or to connect several database servers to form a distributed database system, network failures such as aborted phone connections or network communication software failures can interrupt the normal operation of a database system. For example:
PMON detects and resolves the aborted server process for the disconnected user process, as described in the previous section.RECO of each involved database automatically resolves any distributed transactions not yet resolved at all nodes of the distributed database system.Several structures of an Oracle database safeguard data against possible failures. This section introduces each of these structures and its role in database recovery.
This section contains these topics:
The online redo log, present for every Oracle database, records all changes made in an Oracle database. The online redo log of a database consists of at least two redo log files that are separate from the datafiles (which actually store a database's data). As part of recovery from an instance or media failure, Oracle applies the appropriate changes in the database's redo log to the datafiles, which update database data to the instant that the failure occurred.
Every database must have at least two online redo log groups. Each redo log group contains at least one online redo log member, which is a physical file containing the redo records. If you configure a group to contain multiple members, then you are multiplexing the online redo logs. The multiplexed members of the group contain identical redo data but use different filenames.
Oracle uses and reuses these files in a circular fashion to record database changes. The log file that Oracle is currently writing to is called the current online redo log.
The background process LGWR records all changes made through the associated instance to the current online redo log files. Each redo record contains both the old and the new values. Oracle also records the old value to an undo block located either in a rollback segment (if running in manual undo management mode) or in a dedicated undo tablespace (if running in automatic undo management mode).
Optionally, you can configure an Oracle database to archive copies of the online redo logs after they fill. This type of log is called an archived redo log. An archived log is uniquely identified by its redo thread number and log sequence number. By archiving filled online redo log files, older redo log data is preserved for operations such as media recovery, while the preallocated online redo log files continue to be reused to store the most current database changes.
Datafiles that were restored from backup, or were not closed by a clean shutdown, may not be completely up to date. During recovery, datafiles must be updated by applying the changes in the archived and online redo logs.
You can operate the database in either of two mutually exclusive modes: manual undo management mode, or automatic undo management mode. In the first case, you must create and manage rollback segments. In the case of automatic undo management, you create an undo tablespace that contains system-managed undo segments. Rollback and undo segments are used for a number of functions in the operation of an Oracle database. In general, these segments store the "before image" of data that has been changed by uncommitted transactions.
Among other things, the information in a rollback or undo segment is used during database recovery to undo any uncommitted changes applied from the redo log to the datafiles. Therefore, if database recovery is necessary, then the data is in a consistent state after the rollback segments are used to remove all uncommitted data from the datafiles.
The control files of a database store the status of the physical structure of the database. The control file is absolutely crucial to database operation. It contains (but is not limited to) the following types of information:
Status information in the control file such as the database checkpoints, current online redo log file, and the datafile header checkpoints for the datafiles guides Oracle during crash, instance, or media recovery.
A database can operate in two distinct modes: NOARCHIVELOG mode (media recovery disabled) or ARCHIVELOG mode (media recovery enabled). The database mode has a profound impact on your backup and recovery strategy.
This section contains these topics:
If a database is used in NOARCHIVELOG mode, then the archiving of the online redo log is disabled. Information in the control file indicates that archiving is not required for filled groups. Therefore, as soon as a filled group becomes inactive, the group is available for reuse by the LGWR process.
NOARCHIVELOG mode protects a database only from instance failure, not from media failure. Only the most recent changes made to the database, stored in the groups of the online redo log, are available for crash or instance recovery. These changes are sufficient for crash or instance recovery because Oracle will not overwrite an online log that may be needed until its changes have been recorded in the datafiles. However, it will not be possible to perform media recovery by applying archived redo logs.
If an Oracle database operates in ARCHIVELOG mode, then the archiving of the online redo log is enabled. Information in a database control file indicates that a group of filled online redo log files cannot be reused by LGWR until the group has been archived.
Figure 1-2 illustrates how the database's online redo log files are used in ARCHIVELOG mode and how the archived redo log is generated by the process archiving the filled groups (for example, ARC0 in this illustration).
ARCHIVELOG mode permits complete recovery from disk failure as well as instance failure, because all changes made to the database are permanently saved in an archived redo log.
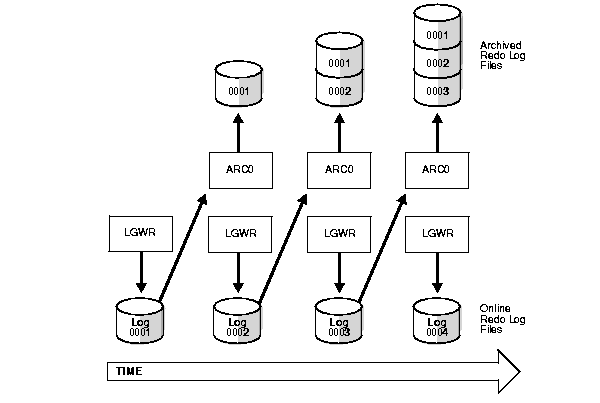
You can configure an instance to have an additional background process, the archiver (ARCn), which automatically archives each group of online redo log files after it becomes an inactive redo log. Automatic archiving frees you from having to keep track of, and archive, filled groups manually. For this convenience alone, automatic archiving is the choice of most database systems that run in ARCHIVELOG mode. For heavy workloads, such as bulk loading of data, multiple archiver processes can be configured by setting the initialization parameter LOG_ARCHIVE_MAX_PROCESSES.
If you request automatic archiving at instance startup by setting the LOG_ARCHIVE_START initialization parameter, then Oracle starts the number of ARCn processes specified by LOG_ARCHIVE_MAX_PROCESSES during instance startup. Otherwise, the ARCn processes are not started when the instance starts up.
You can interactively start or stop automatic archiving at any time. If automatic archiving was not specified to start at instance startup, and if you subsequently start automatic archiving, then Oracle creates the ARCn background processes. ARCn then remains for the duration of the instance, even if automatic archiving is temporarily turned off and on again, although the number of ARCn processes can be changed dynamically by setting LOG_ARCHIVE_MAX_PROCESSES with the ALTER SYSTEM statement.
The archiver always archives groups in order, beginning with the lowest log sequence number. The archiver automatically archives filled groups as they become inactive. A record of every automatic archival is written in the ARCn trace file by the archiver process. Each entry shows the time the archive started and stopped.
If the archiver encounters an error when attempting to archive a log group (for example, due to an invalid or filled destination), then it continues trying to archive the group. An error is also written in the ARCn trace file and the alert-SID.log. If the problem is not resolved, then eventually all online redo log groups become full, yet not archived, and the system stalls because no group is available to LGWR. Therefore, if problems are detected, then you should either resolve the problem so that the archiver can continue archiving (such as by changing the archive destination) or manually archive groups until the problem is resolved.
If a database runs in ARCHIVELOG mode, then you can manually archive the filled groups of inactive online redo log files, as necessary, whether or not automatic archiving is enabled or disabled. If automatic archiving is disabled, then you must manually archive filled groups.
For most database systems, automatic archiving is best because you do not have to watch for a group to become inactive and available for archiving. Furthermore, if automatic archiving is disabled and manual archiving is not performed fast enough, then database operation can be suspended temporarily whenever the log writer is forced to wait for an inactive group to become available for reuse.
The manual archiving option is provided so that you can:
When a group is archived manually, the user process issuing the statement to archive a group actually performs the process of archiving the group. Even if the archiver background process is present for the associated instance, it is the user process that archives the group of online redo log files.
You have two methods for performing Oracle backup and recovery: Recovery Manager (RMAN) and user-managed backup and recovery. RMAN is a utility automatically installed with the database that can back up any Oracle8 or later database. RMAN uses server sessions on the database to perform the work of backup and recovery. RMAN has its own syntax and is accessible either through a command-line interface or though the Oracle Enterprise Manager GUI. RMAN comes with an API that allows it to function with a third-party media manager.
One of the principal advantages of RMAN is that it obtains and stores metadata about its operations in the control file of the production database. You can also set up an independent recovery catalog, which is a schema that contains metadata imported from the control file, in a separate recovery catalog database. RMAN performs the necessary record keeping of backups, archived logs, and so forth using the metadata, so restore and recovery is greatly simplified.
An alternative method of performing recovery is to use operating system commands for backups and SQL*Plus for recovery. This method, also called user-managed backup and recovery, is fully supported by Oracle Corporation, although use of RMAN is highly recommended because it is more robust and greatly simplifies administration.
Whether you use RMAN or user-managed methods, you can supplement your physical backups with logical backups of schema objects made using the Export utility. The utility writes data from an Oracle database to binary operating system files. You can later use Import to restore this data into a database.
See Also:
|
When choosing a backup and recovery solution, find one that is appropriate for the database environment. For example, if you manage only Oracle databases of release 8.0 or higher, then RMAN is an appropriate choice. If you manage some Oracle7 and some post-Oracle7 releases, then you must use a non-RMAN method of backing up the Oracle7 databases.
Table 1-1 describes the version and system requirements for the Oracle backup and recovery methods.
Besides being limited by system requirements, the backup and recovery solution you choose should be driven by the features that you want. Table 1-2 compares the features of the different backup methods.
|
 Copyright © 2001, 2002 Oracle Corporation. All Rights Reserved. |
|

