Release 2 (9.2)
Part Number A96529-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Database Globalization Support Guide Release 2 (9.2) Part Number A96529-01 |
|
This chapter examines globalization support for individual Java components. It includes the following topics:
Java support is included in all tiers of a multitier computing environment so that you can develop and deploy Java programs. You can run Java classes as Java stored procedures on the Java Virtual Machine (Oracle JVM) of the Oracle9i database. You can develop a Java class, load it into the database, and package it as a stored procedure that can be called from SQL.
The JDBC driver and SQLJ translator are also provided as programmatic interfaces that enable Java programs to access the Oracle9i database. You can write a Java application using JDBC or SQLJ programs with embedded SQL statements to access the database. Globalization support is provided across these Java components to ensure that they function properly across databases with different character sets and language environments, and that they enable the development and deployment of multilingual Java applications for Oracle9i.
This chapter examines globalization support for individual Java components. Typical database and client configurations for multilingual application deployment are discussed, including an explanation of how the Java components are used in the configurations. The design and implementation of a sample application are used to demonstrate how Oracle's Java support makes the application run in a multilingual environment.
Java components provide globalization support and use Unicode as the multilingual character set. Table 9-1 shows the Java components of Oracle9i.
Oracle JDBC drivers provide globalization support by allowing you to retrieve data from or insert data into columns of the SQL CHAR and NCHAR datatypes of an Oracle9i database. Because Java strings are encoded as UTF-16 (16-bit Unicode) for JDBC programs, the target character set on the client is always UTF-16. For data stored in the CHAR, VARCHAR2, LONG, and CLOB datatypes, JDBC transparently converts the data from the database character set to UTF-16. For Unicode data stored in the NCHAR, NVARCHAR2, and NCLOB datatypes, JDBC transparently converts the data from the national character set to UTF-16.
The following examples are commonly used Java methods for JDBC that rely heavily on character set conversion:
getString() method of the java.sql.ResultSet class returns values from the database as Java strings.getUnicodeStream() method of the java.sql.ResultSet class returns values as a stream of Unicode characters.getSubString() method of the oracle.sql.CLOB class returns the contents of a CLOB as a Unicode stream.getString(), toString(), and getStringWithReplacement() methods of the oracle.sql.CHAR class return values from the object as java strings.At database connection time, the JDBC Class Library sets the server NLS_LANGUAGE and NLS_TERRITORY parameters to correspond to the locale of the Java VM that runs the JDBC driver. This operation is performed on the JDBC OCI and JDBC thin drivers only, and ensures that the server and the Java client communicate in the same language. As a result, Oracle error messages returned from the server are in the same language as the client locale.
This section includes the following topics:
To insert a Java string into a database column of a SQL CHAR datatype, you can use the PreparedStatement.setString() method to specify the bind variable. Oracle's JDBC drivers transparently convert the Java string to the database character set. The following example shows how to bind a Java string last_name to a VARCHAR2 column last_name.
int employee_id= 12345; String last_name= "\uFF2A\uFF4F\uFF45"; PreparedStatement pstmt = conn.prepareStatement ("INSERT INTO employees (employee_id, last_name) VALUES(?,?)");pstmt.setInt(1, employee_id); pstmt.setString(2, last_name); pstmt.execute(); pstmt.close();
For data stored in SQL CHAR datatypes, the techniques that Oracle's drivers use to perform character set conversion for Java applications depend on the character set that the database uses. The simplest case is when the database uses a US7ASCII or WE8ISO8859P1 character set. In this case, the driver converts the data directly from the database character set to UTF-16,which is used in Java applications.
If you are working with databases that employ a character set that is not US7ASCII or WE8ISO8859P1 (for example, JA16SJIS or KO16KSC5601), then the driver converts the data first to UTF-8, then to UTF-16. The following sections describe the conversion paths for different JDBC drivers:
Figure 9-1 shows how data is converted in JDBC drivers.
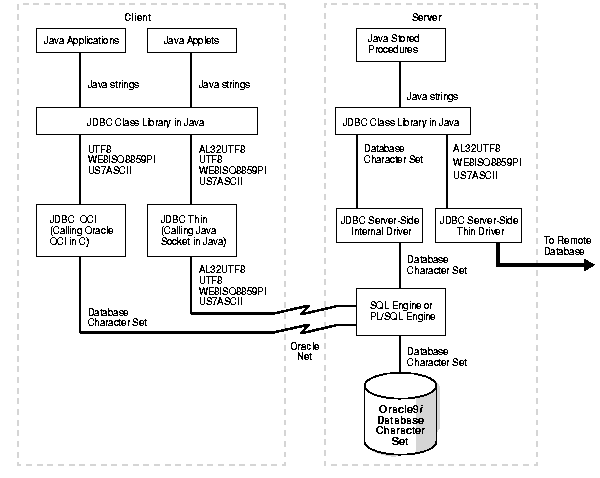
The JDBC Class Library is a Java layer that implements the JDBC interface. Java applications, applets, and stored procedures interact with this layer. The library always accepts US7ASCII, UTF8, or WE8ISO8859P1 encoded string data from the input stream of the JDBC drivers. It also accepts AL32UTF8 data for the JDBC thin driver and database character set data for the JDBC server-side driver. The JDBC Class Library converts the input stream to UTF-16 before passing it to the client applications. AL32UTF8 is another character set in addition to UTF8 for encoding Unicode characters in the UTF-8 encoding. It supports supplemental Unicode characters. If the input stream is in UTF8 or AL32UTF8, then the JDBC Class Library converts the UTF8 or AL32UTF8 encoded string to UTF-16 by using the bit-wise operation defined in the UTF-8 to UTF-16 conversion algorithm. If the input stream is in US7ASCII or WE8ISO8859P1, then it converts the input string to UTF-16 by casting the bytes to Java characters. If the input stream is not one of US7ASCII, WE8ISO8859P1, UTF8 and AL32UTF8, then the JDBC Class Library converts the input stream by calling the Oracle character set conversion facility. This conversion path is only used for the JDBC server-side driver.
In the case of a JDBC OCI driver, there is a client-side character set as well as a database character set. The client character set is determined at client start time by the value of the NLS_LANG environment variable on the client. The database character set is determined at database creation. The character set used by the client can be different from the character set used by the database on the server. When performing character set conversion, the JDBC OCI driver has to take three factors into consideration:
The JDBC OCI driver transfers the data from the server to the client in the character set of the database. Depending on the value of the NLS_LANG environment variable, the driver handles character set conversions in one of two ways:
NLS_LANG is not specified, or if it is set to the US7ASCII or WE8ISO8859P1 character set, then the JDBC OCI driver uses Java to convert the character set from US7ASCII or WE8ISO8859P1 directly to UTF-16 in the JDBC Class Library.NLS_LANG is set to a character set other than US7ASCII or WE8ISO8859P1, then the driver uses UTF8 as the client character set. This happens automatically and does not require any user intervention. OCI then converts the data from the database character set to UTF8. The JDBC OCI driver then passes the UTF8 data to the JDBC Class Library where the UTF8 data is converted to UTF-16.If applications or applets use the JDBC thin driver, then there is no Oracle client installation. Because of this, the OCI client conversion routines in C are not available. In this case, the client conversion routines of the JDBC thin driver are different from conversion routines of the JDBC OCI driver.
If the database character set is US7ASCII, WE8ISO8859P1, UTF8, or AL32UTF8, then the data is transferred to the client without any conversion. The JDBC Class Library then converts the data to UTF-16 in Java.
Otherwise, the server first translates the data to UTF8 or AL32UTF8 before transferring it to the client. On the client, the JDBC Class Library converts the data to UTF-16 in Java.
For Java classes running in the Java VM of the Oracle9i Server, the JDBC server-side internal driver is used to talk to the SQL engine or the PL/SQL engine for SQL processing. Because the JDBC server-side internal driver is running in the same address space as the Oracle server process, it makes a local function call to the SQL engine or the PL/SQL engine. Data sent to or returned from the SQL engine or the PL/SQL engine is encoded in the database character set, No data conversion is performed in the JDBC server-side internal driver, and the data is passed to or from the JDBC Class Library as is. Any necessary conversion is delegated to the JDBC Class Library.
JDBC enables Java programs to access columns of the SQL NCHAR datatypes in an Oracle9i database. Data conversion for the SQL NCHAR datatypes is different from data conversion for the SQL CHAR datatypes. All Oracle JDBC drivers convert data in the SQL NCHAR column from the national character set, which is either UTF8 or AL16UTF16, directly to UTF-16 encoded Java strings. In the following Java program, you can bind a Java string last_name to an NVARCHAR2 column last_name:
int employee_id = 12345; String ename = "\uFF2A\uFF4F\uFF45"; oracle.jdbc.OraclePreparedStatement pstmt = (oracle.jdbc.OraclePreparedStatement) conn.prepareStatement("INSERT INTO employees (empoyee_id, last_name) VALUES (?, ?)"); pstmt.setFormOfUse(2, oracle.jdbc.OraclePreparedStatement.FORM_NCHAR); pstmt.setInt(1, employee_id); pstmt.setString(2, last_name); pstmt.execute(); pstmt.close();
| See Also:
"Binding and Defining Java Strings in Unicode" for more information about programming against the SQL |
The oracle.sql.CHAR class has a special functionality for conversion of character data. The Oracle character set is a key attribute of the oracle.sql.CHAR class. The Oracle character set is always passed in when an oracle.sql.CHAR object is constructed. Without a known character set, the bytes of data in the oracle.sql.CHAR object are meaningless.
The oracle.sql.CHAR class provides the following methods for converting character data to strings:
getString()
Converts the sequence of characters represented by the oracle.sql.CHAR object to a string, returning a Java String object. If the character set is not recognized, then getString() returns a SQLException.
toString()
Identical to getString(), except that if the character set is not recognized, then toString() returns a hexadecimal representation of the oracle.sql.CHAR data and does not returns a SQLException.
getStringWithReplacement()
Identical to getString(), except that a default replacement character replaces characters that have no Unicode representation in the character set of this oracle.sql.CHAR object. This default character varies among character sets, but it is often a question mark.
You may want to construct an oracle.sql.CHAR object yourself (to pass into a prepared statement, for example). When you construct an oracle.sql.CHAR object, you must provide character set information to the oracle.sql.CHAR object by using an instance of the oracle.sql.CharacterSet class. Each instance of the oracle.sql.CharacterSet class represents one of the character sets that Oracle supports.
Complete the following tasks to construct an oracle.sql.CHAR object:
CharacterSet instance by calling the static CharacterSet.make() method. This method creates the character set class. It requires as input a valid Oracle character set (OracleId). For example:
int OracleId = CharacterSet.JA16SJIS_CHARSET; // this is character set 832 ... CharacterSet mycharset = CharacterSet.make(OracleId);
Each character set that Oracle supports has a unique predefined OracleId. The OracleId can always be referenced as a character set specified as Oracle_character_set_name_CHARSET where Oracle_character_set_name is the Oracle character set.
oracle.sql.CHAR object. Pass to the constructor a string (or the bytes that represent the string) and the CharacterSet object that indicates how to interpret the bytes based on the character set. For example:
String mystring = "teststring"; ... oracle.sql.CHAR mychar = new oracle.sql.CHAR(teststring, mycharset);
The oracle.sql.CHAR class has multiple constructors: they can take a string, a byte array, or an object as input along with the CharacterSet object. In the case of a string, the string is converted to the character set indicated by the CharacterSet object before being placed into the oracle.sql.CHAR object.
The server (database) and the client (or application running on the client) can use different character sets. When you use the methods of this class to transfer data between the server and the client, the JDBC drivers must convert the data between the server character set and the client character set.
When you call the OracleResultSet.getCHAR() method to get a bind variable as an oracle.sql.CHAR object, JDBC constructs and populates the oracle.sql.CHAR objects after character data has been read from the database. Similarly, you can call the OraclePreparedStatement.sql.CHAR() method to set a bind variable using an oracle.sql.CHAR object. For example:
int employee_id = 12345; String ename = "\uFF2A\uFF4F\uFF45"; String eaddress = "Address of \uFF2A\uFF4F\uFF45"; /* CharacterSet object for VARCHAR2 column */ CharacterSet dbCharset = CharacterSet.make(CharacterSet.JA16SJIS_CHARSET); /* CharacterSet object for NVARCHAR2 column */ CharacterSet ncCharset = CharacterSet.make(CharacterSet.AL16UTF16_CHARSET); /* last_name is in VARCHAR2 and address is in NVARCHAR2 */ oracle.jdbc.OraclePreparedStatement pstmt = (oracle.jdbc.OraclePreparedStatement) conn.prepareStatement("INSERT INTO employees (empoyee_id, last_name, address) VALUES (?, ?, ?)"); pstmt.setFormOfUse(3, oracle.jdbc.OraclePreparedStatement.FORM_NCHAR); pstmt.setInt(1, employee_id); pstmt.setCHAR(2, new oracle.sql.CHAR(ename, dbCharset)); pstmt.setCHAR(3, new oracle.sql.CHAR(eaddress, ncCharset)); pstmt.execute(); pstmt.close();
In Oracle9i, JDBC drivers support Oracle object types. Oracle objects are always sent from database to client as an object represented in the database character set. That means the data conversion path in Figure 9-1 does not apply to Oracle object access. Instead, the oracle.sql.CHAR class is used for passing SQL CHAR and SQL NCHAR data of an object type from the database to the client. The following is an example of an object type created using SQL:
CREATE TYPE person_type AS OBJECT (name VARCHAR2(30), address NVARCHAR(256), age NUMBER); CREATE TABLE employees (id NUMBER, person PERSON_TYPE);
The Java class corresponding to this object type can be constructed as follows:
public class person implement SqlData { oracle.sql.CHAR name; oracle.sql.CHAR address; oracle.sql.NUMBER age; // SqlData interfaces getSqlType() {...} writeSql(SqlOutput stream) {...} readSql(SqlInput stream, String sqltype) {...} }
The oracle.sql.CHAR class is used here to map to the NAME attributes of the Oracle object type, which is of VARCHAR2 datatype. JDBC populates this class with the byte representation of the VARCHAR2 data in the database and the CharacterSet object corresponding to the database character set. The following code retrieves a person object from the employees table:
TypeMap map = ((OracleConnection)conn).getTypeMap(); map.put("PERSON_TYPE", Class.forName("person")); conn.setTypeMap(map); . . . . . . ResultSet rs = stmt.executeQuery("SELECT PERSON FROM EMPLOYEES"); rs.next(); person p = (person) rs.getObject(1); oracle.sql.CHAR sql_name = p.name; oracle.sql.CHAR sql_address=p.address; String java_name = sql_name.getString(); String java_name = sql_address.getString();
The getString() method of the oracle.sql.CHAR class converts the byte array from the database character set to UTF-16 by calling Oracle's Java data conversion classes and returning a Java string. For the rs.getObject(1) call to work, the SqlData interface has to be implemented in the class person, and the Typemap map has to be set up to indicate the mapping of the object type PERSON_TYPE to the Java class.
This section contains the following topics:
If the database character set is neither ASCII (US7ASCII) nor ISO Latin1 (WE8ISO8859P1), then the JDBC thin driver must impose size restrictions for SQL CHAR bind parameters that are more restrictive than normal database size limitations. This is necessary to allow for data expansion during conversion.
The JDBC thin driver checks SQL CHAR bind sizes when a setXXX() method (except for the setCharacterStream() method) is called. If the data size exceeds the size restriction, then the driver returns a SQL exception (SQLException: Data size bigger than max size for this type") from the setXXX() call. This limitation is necessary to avoid the chance of data corruption when conversion of character data occurs and increases the length of the data. This limitation is enforced in the following situations:
CHAR datatypesWhen the database character set is neither US7ASCII nor WE8ISO8859P1, the JDBC thin driver converts Java UTF-16 characters to UTF-8 encoding bytes for SQL CHAR binds. The UTF-8 encoding bytes are then transferred to the database, and the database converts the UTF-8 encoding bytes to the database character set encoding.
This conversion to the character set encoding can result in an increase in the number of bytes required to store the data. The expansion factor for a database character set indicates the maximum possible expansion in converting from UTF-8 to the character set. If the database character set is either UTF8 or AL32UTF8, then the expansion factor (exp_factor) is 1. Otherwise, the expansion factor is equal to the maximum character size (measured in bytes) in the database character set.
Table 9-2 shows the database size limitations for SQL CHAR data and the JDBC thin driver size restriction formulas for SQL CHAR binds. Database limits are in bytes. Formulas determine the maximum allowed size of the UTF-8 encoding in bytes.
The formulas guarantee that after the data is converted from UTF-8 to the database character set, the size of the data will not exceed the maximum size allowed in the database.
The number of UTF-16 characters that can be supported is determined by the number of bytes per character in the data. All ASCII characters are one byte long in UTF-8 encoding. Other character types can be two or three bytes long.
Table 9-3 lists the expansion factors of some common server character sets. It also shows the JDBC thin driver maximum bind sizes for CHAR and VARCHAR2 data for each character set.
Oracle JDBC drivers perform character set conversions as appropriate when character data is inserted into or retrieved from the database. The drivers convert Unicode characters used by Java clients to Oracle database character set characters, and vice versa. Character data that makes a round trip from the Java Unicode character set to the database character set and back to Java can suffer some loss of information. This happens when multiple Unicode characters are mapped to a single character in the database character set. An example is the Unicode full-width tilde character (0xFF5E) and its mapping to Oracle's JA16SJIS character set. The round trip conversion for this Unicode character results in the Unicode character 0x301C, which is a wave dash (a character commonly used in Japan to indicate range), not a tilde.
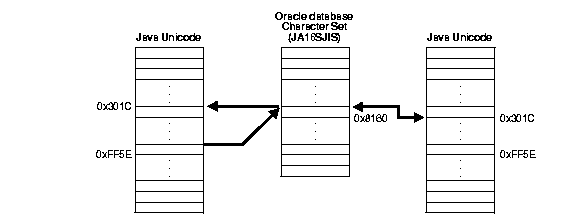
This issue is not a bug in Oracle's JDBC. It is an unfortunate side effect of the ambiguity in character mapping specification on different operating systems. Fortunately, this problem affects only a small number of characters in a small number of Oracle character sets such as JA16SJIS, JA16EUC, ZHT16BIG5, and KO16KS5601. The workaround is to avoid making a full round-trip with these characters.
SQLJ is a SQL-to-Java translator that translates embedded SQL statements in a Java program into the corresponding JDBC calls regardless of which JDBC driver is used. It also provides a callable interface that the Oracle9i database server uses to transparently translate the embedded SQL in server-side Java programs. SQLJ by itself is a Java application that reads the SQLJ programs (Java programs containing embedded SQL statements) and generates the corresponding Java program files with JDBC calls. There is an option to specify a checker to check the embedded SQL statements against the database at translation time. The javac compiler is then used to compile the generated Java program files to regular Java class files.
Figure 9-3 shows how the SQLJ translator works. The figure is described in the following sections:
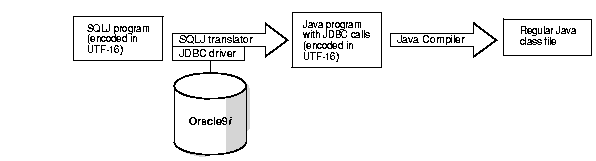
SQLJ enables multilingual Java application development by allowing SQLJ files encoded in different encoding schemes (those supported by the JDK). In Figure 9-3, a UTF-16 encoded SQLJ program is being passed to the SQLJ translator and the Java program output is also encoded in UTF-16. SQLJ preserves the encoding of the source in the target. To specify the encoding of the source, use the -encoding option as follows:
sqlj -encoding Unicode source_file
Unicode notation \uXXXX (which is referred to as a Unicode escape sequence) can be used in embedded SQL statements for characters that cannot be represented in the encoding of the SQLJ program file. This enables you to specify multilingual object names in the SQL statement without using a UTF-16-encoded SQLJ file. The following SQLJ code shows the use of Unicode escape sequences in embedded SQL as well as in a string literal.
int employee_id = 12345; String name last_name = "\uFF2A\uFF4F\uFF45"; double raise = 0.1; #sql { INSERT INTO E\u006D\u0070 (last_name, employee_id) VALUES (:last_name, :employee_id)}; #sql { UPDATE employees SET salary = :(getNewSal(raise, last_name)) WHERE last_name = :last_name};
| See Also:
"A Multilingual Demo Application in SQLJ" for an example of SQLJ usage for a multilingual Java application |
In Oracle9i, the oracle.sql.NString class is introduced in SQLJ to support the NVARCHAR2, NCHAR, and NCLOB Unicode datatypes. You can declare a bind on NCHAR column using a Java object of the oracle.sql.NString type, and use it in the embedded SQL statements in SQLJ programs.
int employee_id = 12345; oracle.sql.NString last_name = new oracle.sql.NString ("\uFF2A\uFF4F\uFF45"); double raise = 0.1; #sql { INSERT INTO E\u006D\u0070 (last_name, employee_id VALUES (:last_name, :employee_id)}; #sql { UPDATE employees SET salary = :(getNewSal(raise, last_name)) = :last_ name};
This example binds the last_name object of the oracle.sql.NString datatype to the last_name database NVARCHAR2 column.
| See Also:
"Binding and Defining Java Strings in Unicode" for more details on the SQL |
The Oracle9i Java Virtual Machine (Java VM) is integrated into the database server to enable the running of Java classes stored in the database. Oracle9i enables you to store Java class files, Java or SQLJ source files, and Java resource files into the database. Then the Java entry points to SQL can be published so that Java can be called from SQL or PL/SQL and the Java byte code can be run.
In addition to the engine that interprets Java byte code, the Oracle Java VM includes the core runtime classes of the Java Development Kit (JDK). The components of the Java VM are depicted in Figure 9-4.
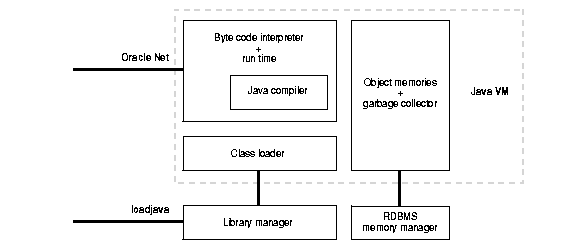
The Java VM provides:
A library manager is also included to manage Java program, class, and resource files as schema objects known as library units. It not only loads and manages these Java files in the database, but also maps Java name space to library units. For example:
public class Greeting { public String Hello(String name) { return ("Hello" + name + "!"); } }
After the preceding Java code is compiled, it is loaded into the database as follows:
loadjava Greeting.class
As a result, a library unit called Greeting is created as a schema object in the database.
Class and method names containing characters that cannot be represented in the database character set are handled by generating a US7ASCII library unit name and mapping it to the real class name stored in a RAW column. This enables the class loader to find the library unit corresponding to the real class name when Java programs run in the server. In other words, the library manager and the class loader support class names or method names outside the namespace of the database character set.
A Java stored procedure or function requires that the library unit of the Java classes implementing it already be present in the database. Using the Greeting library unit example in the previous section, the following call data definition language (DDL) publishes the method Greeting.Hello() as a Java stored function:
CREATE FUNCTION myhello(name VARCHAR2) RETURN VARCHAR2 AS LANGUAGE JAVA NAME 'Greeting.Hello(java.lang.String) return java.lang.String';
The DDL maps the Java methods, parameter types and return types to the SQL counterparts. To the users, the Java stored function has the same calling syntax as any other PL/SQL stored function. Users can call the Java stored procedures the same way they call any PL/SQL stored procedures.
Figure 9-5 depicts the runtime environment of a stored function.
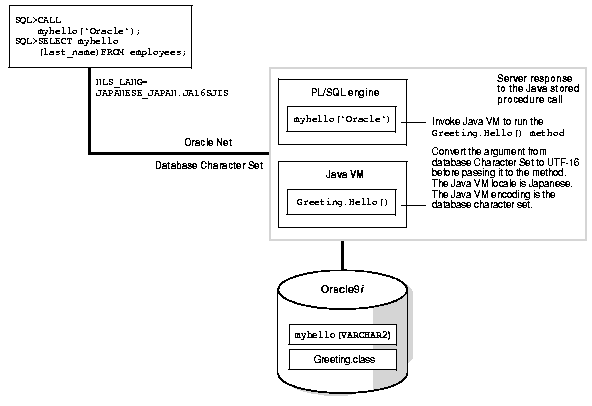
The locale of the Java VM is Japanese and its encoding is the database character set. The client's NLS_LANG environment variable is defined as JAPANESE_JAPAN.JA16SJIS. Oracle Net converts the JA16SJIS characters in the client to the database character set characters if the characters are different.
The Java entry point, Greeting.Hello(), is called by invoking the proxy PL/SQL myhello() from the client. The server process serving the client runs as a normal PL/SQL stored function and uses the same syntax. The PL/SQL engine takes a call specification for a Java method and calls the Java VM. Next, it passes the method name of the Java stored function and the argument to the Java VM for execution. The Java VM takes control, calls the SQL to Java using code to convert the VARCHAR2 argument from the database character set to UTF-16, loads the Greeting class, and runs the Hello() method with the converted argument. The string returned by Hello() is then converted back to the database character set and returned as a VARCHAR2 string to the caller.
The globalization support that enables deployment and development of internationalized Java stored procedures includes:
NLS_LANG environment variable of the client. A mapping of Oracle language and territory names to Java locale names is in place for this purpose. In additions, the default encoding of the Java VM follows the database character set.loadjava utility supports loading of Java and SQLJ source files encoded in any encoding supported by the JDK. The content of the Java or SQLJ program is not limited by the database character set. Unicode escape sequences are also supported in the program files.
To develop and deploy multilingual Java applications for Oracle9i, the database configurations and client environments for the targeted systems must be determined.
This section contains the following topics:
In order to store multilingual data in an Oracle9i database, you need to configure the database appropriately. There are two ways to store Unicode data into the database:
CHAR datatypes in a Unicode databaseNCHAR datatypes in a non-Unicode database
| See Also:
Chapter 5, "Supporting Multilingual Databases with Unicode" for more information about choosing a Unicode solution and configuring the database for Unicode |
For each Oracle9i session, a separate Java VM instance is created in the server for running the Java stored procedure, and Oracle9i Java support ensures that the locale of the Java VM instance is the same as that of the client Java VM. Hence the Java stored procedures always run on the same locale in the database as the client locale.
For non-Java clients, the default locale of the Java VM instance will be the Java locale that best corresponds to the NLS_LANGUAGE and NLS_TERRITORY session parameters propagated from the client NLS_LANG environment variable.
Java stored procedures are server objects which are accessible from clients of different language preferences. They should be internationalized so that they are sensitive to the Java locale of the Java VM, which is initialized to the locale of the client.
With JDK internationalization support, you can specify a Java locale object to any locale-sensitive methods or use the default Java locale of the Java VM for those methods. The following are examples of how to internationalize a Java stored procedure:
DateFormat and NumberFormat to format the date, time, numbers, and currencies with the assumption that they will reflect the locale of the calling client.Character, Collator, and BreakIterator to check the classification of a character, compare two strings linguistically, and parse a string character by character.All Java server objects access the database with the JDBC server-side internal driver and should use either a Java string or oracle.sql.CHAR to represent string data to and from the database. Java strings are always encoded in UTF-16, and the required conversion from the database character set to UTF-16 is done transparently. oracle.sql.CHAR stores the database data in byte array and tags it with a character set ID. oracle.sql.CHAR should be used when no string manipulation is required on the data. For example, it is the best choice for transferring string data from one table to another in the database.
Clients (or middle tiers) can have different language preferences, database access mechanisms, and Java runtime environments. The following are several commonly used client configurations.
Java applets running in browsers can access the Oracle9i database through the JDBC thin driver. No client-side Oracle library is required. The applets use the JDBC thin driver to invoke SQL, PL/SQL as well as Java stored procedures. The JDBC thin driver makes sure that Java stored procedures run in the same locale as the Java VM running the applets.
HTML pages invoke Java servlets by using URLs over HTTP. The Java servlets running in the middle tier construct dynamic HTML pages and deliver them back to the browser. They should determine the locale of a user and construct the page according to the language and cultural convention preferences of the user and use JDBC to connect to the database.
Java applications running on the Java VM of the client machine can access the database through either JDBC OCI or JDBC thin drivers. Java applications can also be a middle tier servlet running on a Web server. The applications use JDBC drivers to invoke SQL, PL/SQL as well as Java stored procedures. The JDBC Thin and JDBC OCI drivers make sure that Java stored procedures will be running in the same locale as that of the client Java VM.
Non-Java clients can call Java stored procedures the same way they call PL/SQL stored procedures. The Java VM locale is the best match of Oracle's language settings NLS_LANGUAGE and NLS_TERRITORY propagated from the NLS_LANG environment variable of the client. As a result, the client always gets messages from the server in the language specified by NLS_LANG. Data in the client are converted to and from the database character set by OCI.
This section contains a simple bookstore application written in SQLJ to demonstrate a database storing book information in different languages, and how SQLJ and JDBC are used to access the book information from the database. It also demonstrates the use of internationalized Java stored procedures to accomplish transactional tasks in the database server. The sample program consists of the following components:
This section contains the following topics:
AL32UTF8 is the database character set that is used to store book information, such as names and authors, in languages around the world.
The book table is described in Table 9-4.
| Column Name | Datatype |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The inventory table is described in Table 9-5.
| Column Name | Datatype |
|---|---|
|
|
|
|
|
|
|
|
|
In addition, indexes are built with the NAME and AUTHOR columns of the book table to improve performance during book searches. A BOOKSEQ sequence is be created to generate a unique book ID.
The Java class called Book is created to implement the methods Book.remove() and Book.add() that perform the tasks of removing books from and adding books to the inventory respectively. They are defined according to the following code. In this class, only the remove() method and the constructor are shown. The resource bundle BookRes.class is used to store localizable messages. The remove() method returns a message gotten from the resource bundle according to the current Java VM locale. There is no JDBC connection required to access the database because the stored procedure is already running in the context of a database session.
import java.sql.*; import java.util.*; import sqlj.runtime.ref.DefaultContext; /* The book class implementation the transaction logics of the Java stored procedures.*/ public class Book { static ResourceBundle rb; static int q, id; static DefaultContext ctx; public Book() { try { DriverManager.registerDriver(new oracle.jdbc.driver.OracleDriver()); DefaultContext.setDefaultContext(ctx); rb = java.util.ResourceBundle.getBundle("BookRes"); } catch (Exception e) { System.out.println("Transaction failed: " + e.getMessage()); } } public static String remove(int id, int quantity, String location) throws SQLException { rb = ResourceBundle.getBundle("BookRes"); try { #sql {SELECT QUANTITY INTO :q FROM INVENTORY WHERE ID = :id AND LOCATION = :location}; if (id == 1) return rb.getString ("NotEnough"); } catch (Exception e) { return rb.getString ("NotEnough"); } if ((q - quantity) == 0) { #sql {DELETE FROM INVENTORY WHERE ID = :id AND LOCATION = :location}; try { #sql {SELECT SUM(QUANTITY) INTO :q FROM INVENTORY WHERE ID = :id}; } catch (Exception e) { #sql { DELETE FROM BOOK WHERE ID = :id }; return rb.getString("RemoveBook"); } return rb.getString("RemoveInventory"); } else { if ((q-quantity) < 0) return rb.getString ("NotEnough"); #sql { UPDATE INVENTORY SET QUANTITY = :(q-quantity) WHERE ID = :id and LOCATION = :location }; return rb.getString("DecreaseInventory"); } } public static String add( String bname, String author, String location, double price, int quantity, String publishdate ) throws SQLException { rb = ResourceBundle.getBundle("BookRes"); try { #sql { SELECT ID into :id FROM BOOK WHERE NAME = :bname AND AUTHOR = :author }; } catch (Exception e) { #sql { SELECT BOOKSEQ.NEXTVAL INTO :id FROM DUAL }; #sql { INSERT INTO BOOK VALUES (:id, :bname, TO_DATE(:publishdate,'YYYY-MM-DD'), :author, :price) }; #sql { INSERT INTO INVENTORY VALUES (:id, :location, :quantity) }; return rb.getString("AddBook"); } try { #sql { SELECT QUANTITY INTO :q FROM INVENTORY WHERE ID = :id AND LOCATION = :location }; } catch (Exception e) { #sql { INSERT INTO INVENTORY VALUES (:id, :location, :quantity) }; return rb.getString("AddInventory"); } #sql { UPDATE INVENTORY SET QUANTITY = :(q + quantity) WHERE ID = :id AND LOCATION = :location }; return rb.getString("IncreaseInventory"); } }
After the Book.remove() and Book.add() methods are defined, they are in turn published as Java stored functions in the database called REMOVEBOOK() and ADDBOOK():
CREATE FUNCTION REMOVEBOOK (ID NUMBER, QUANTITY NUMBER, LOCATION VARCHAR2) RETURN VARCHAR2 AS LANGUAGE JAVA NAME 'Book.remove(int, int, java.lang.String) return java.lang.String'; CREATE FUNCTION ADDBOOK (NAME VARCHAR2, AUTHOR VARCHAR2, LOCATION VARCHAR2, PRICE NUMBER, QUANTITY NUMBER, PUBLISH_DATE DATE) RETURN VARCHAR2 AS LANGUAGE JAVA NAME 'Book.add(java.lang.String, java.lang.String, java.lang.String, double, int, java.sql.Date) return java.lang.String';
Note that the Java string returned is first converted to a VARCHAR2 string, which is encoded in the database character set, before they are passed back to the client. If the database character set is not AL32UTF8 or UTF8, then any Unicode characters in the Java strings that cannot be represented in the database character set will be replaced by a replacement character. Similarly, the VARCHAR2 strings, which are encoded in the database character set, are converted to Java strings before being passed to the Java methods.
The SQLJ client is a GUI Java application using either a JDBC Thin or JDBC OCI driver. It connects the client to a database, displays a list of books given a searching criterion, removes selected books from the inventory, and adds new books to the inventory. A class called BookDB is created to accomplish these tasks. It is defined in the following code.
A BookDB object is created when the sample program starts up with the user name, password, and the location of the database. The methods are called from the GUI portion of the applications. The removeBook() and addBook() methods call the corresponding Java stored functions in the database and return the status of the transaction. The methods searchByName() and searchByAuthor() list books by name and author respectively, and store the results in the books iterator inside the BookDB object. (The BookRecs class is generated by SQLJ.) The GUI code in turn calls the getNextBook() function to retrieve the list of books from the iterator object until a NULL is returned. The getNextBook() function simply fetches the next row from the iterator.
package sqlj.bookstore; import java.sql.*; import sqlj.bookstore.BookDescription; import sqlj.runtime.ref.DefaultContext; import java.util.Locale; /*The iterator used for a book description when communicating with the server*/ #sql iterator BooksRecs( int ID, String NAME, String AUTHOR, Date PUBLISH_DATE, String LOCATION, int QUANTITY, double PRICE); /*This is the class used for connection to the server.*/ class BookDB { static public final String DRIVER = "oracle.jdbc.driver.OracleDriver"; static public final String URL_PREFIX = "jdbc:oracle:thin:@"; private DefaultContext m_ctx = null; private String msg; private BooksRecs books; /*Constructor - registers the driver*/ BookDb() { try { DriverManager.registerDriver ((Driver) (Class.forName(DRIVER).newInstance())); } catch (Exception e) { System.exit(1); } } /*Connect to the database.*/ DefaultContext connect(String id, String pwd, String userUrl) throws SQLException { String url = new String(URL_PREFIX); url = url.concat(userUrl); Connection conn = null; if (m_ctx != null) return m_ctx; try { conn = DriverManager.getConnection(url, id, pwd); } catch (SQLException e) { throw(e); } if (m_ctx == null) { try { m_ctx = new DefaultContext(conn); } catch (SQLException e) { throw(e); } } return m_ctx; } /*Add a new book to the database.*/ public String addBook(BookDescription book) { String name = book.getTitle(); String author = book.getAuthor(); String date = book.getPublishDateString(); String location = book.getLocation(); int quantity = book.getQuantity(); double price = book.getPrice(); try { #sql [m_ctx] msg = {VALUE ( ADDBOOK ( :name, :author, :location, :price, :quantity, :date))}; #sql [m_ctx] {COMMIT}; } catch (SQLException e) { return (e.getMessage()); } return msg; } /*Remove a book.*/ public String removeBook(int id, int quantity, String location) { try { #sql [m_ctx] msg = {VALUE ( REMOVEBOOK ( :id, :quantity, :location))}; #sql [m_ctx] {COMMIT}; } catch (SQLException e) { return (e.getMessage()); } return msg; } /*Search books by the given author.*/ public void searchByAuthor(String author) { String key = "%" + author + "%"; books = null; System.gc(); try { #sql [m_ctx] books = { SELECT BOOK.ID, NAME, AUTHOR, PUBLISH_DATE, LOCATION, QUANTITY, PRICE FROM BOOK, INVENTORY WHERE BOOK.ID = INVENTORY.ID AND AUTHOR LIKE :key ORDER BY BOOK.ID}; } catch (SQLException e) {} } /*Search books with the given title.*/ public void searchByTitle(String title) { String key = "%" + title + "%"; books = null; System.gc(); try { #sql [m_ctx] books = { SELECT BOOK.ID, NAME, AUTHOR, PUBLISH_DATE, LOCATION, QUANTITY, PRICE FROM BOOK, INVENTORY WHERE BOOK.ID = INVENTORY.ID AND NAME LIKE :key ORDER BY BOOK.ID}; } catch (SQLException e) {} } /*Returns the next BookDescription from the last search, null if at the end of the result list.*/ public BookDescription getNextBook() { BookDescription book = null; try { if (books.next()) { book = new BookDescription(books.ID(), books.AUTHOR(), books.NAME(), books.PUBLISH_DATE(), books.PRICE(), books.LOCATION(), books.QUANTITY()); } } catch (SQLException e) {} return book; } }
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|

