Release 2 (9.2)
Part Number A96544-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Heterogeneous Connectivity Administrator's Guide Release 2 (9.2) Part Number A96544-01 |
|
This chapter describes the major features provided by Oracle Transparent Gateways and Generic Connectivity. Descriptions of these features are contained in the following topics:
SQL statements are translated and data types are mapped according to capabilities. PL/SQL calls are mapped to non-Oracle system stored procedures. In the case of SQL statements, if functionality is missing at the remote system, then either a simpler query is issued or the statement is broken up into multiple queries and the desired results are obtained by post processing in the Oracle database.
Even though Heterogeneous Services can, for the most part, incorporate non-Oracle systems into Oracle distributed sessions, there are several limitations to this. Some of the generic limitations are:
INSERT INTO remote_table@link as SELECT * FROM local_table;
CONNECT BY clauses in SQL statements.SELECT remote_func@link(a,b) FROM remote_table@link
out arguments of type REF CURSOR but not in or in-out objects.Data can be replicated between a non-Oracle system and an Oracle server using materialized views.
|
Note: Starting with Oracle9i, Release 2, there is another means of sharing information between databases. Called Streams, this functionality includes the replication of information between Oracle and non-Oracle databases. For information about using Streams, see Oracle9i Streams. |
Materialized views instantiate data captured from tables at the non-Oracle master site at a particular point in time. This instant is defined by a refresh operation, which copies this data to the Oracle server and synchronizes the copy on Oracle with the master copy on the non-Oracle system. The "materialized" data is then available as a view on the Oracle server.
Replication facilities provide mechanisms to schedule refreshes and to collect materialized views into replication groups to facilitate their administration. Refresh groups permit refreshing multiple materialized views just as if they were a single object.
Heterogeneous replication support is necessarily limited to a subset of the full Oracle-to-Oracle replication functionality:
Other restrictions apply to any access to non-Oracle data through Oracle's Heterogeneous Services facilities. The most important of these are:
The following examples illustrate basic setup and use of three materialized views to replicate data from a non-Oracle system to an Oracle data store.
|
Note: For the following examples, |
This example creates three materialized views that are then used in succeeding examples.
customer@remote_db.
CREATE MATERIALIZED VIEW pk_mv REFRESH COMPLETE AS SELECT * FROM customer@remote_db WHERE "zip" = 94555;
orders@remote_db and customer@remote_db.
CREATE MATERIALIZED VIEW sq_mv REFRESH COMPLETE AS SELECT * FROM orders@remote_db o WHERE EXISTS (SELECT c."c_id" FROM customer@remote_db c WHERE c."zip" = 94555 and c."c_id" = o."c_id" );
remote_db.
CREATE MATERIALIZED VIEW cx_mv REFRESH COMPLETE AS SELECT c."c_id", o."o_id" FROM customer@remote_db c, orders@remote_db o, order_line@remote_db ol WHERE c."c_id" = o."c_id" AND o."o_id" = ol."o_id";
BEGIN dbms_refresh.make('refgroup1', 'pk_mv, sq_mv, cx_mv', NULL, NULL); END; /
BEGIN dbms_refresh.refresh('refgroup1'); END; /
| See Also:
Oracle9i Replication for a full description of materialized views and replication facilities |
The pass-through SQL feature enables you to send a statement directly to a non-Oracle system without being interpreted by the Oracle9i server. This feature can be useful if the non-Oracle system allows for operations in statements for which there is no equivalent in Oracle.
This section contains the following topics:
You can execute pass-through SQL statements directly at the non-Oracle system using the PL/SQL package DBMS_HS_PASSTHROUGH. Any statement executed with this package is executed in the same transaction as standard SQL statements.
The DBMS_HS_PASSTHROUGH package is a virtual package. It conceptually resides at the non-Oracle system. In reality, however, calls to this package are intercepted by Heterogeneous Services and mapped onto one or more Heterogeneous Services application programming interface (API) calls. The driver, in turn, maps these Heterogeneous Services API calls onto the API of the non-Oracle system. The client application should invoke the procedures in the package through a database link in exactly the same way as it would invoke a non-Oracle system stored procedure. The special processing done by Heterogeneous Services is transparent to the user.
| See Also:
Oracle9i Supplied PL/SQL Packages and Types Reference for more information about this package |
When you execute a pass-through SQL statement that implicitly commits or rolls back a transaction in the non-Oracle system, the transaction is affected. For example, some systems implicitly commit the transaction containing a data definition language (DDL) statement. Because the Oracle database server is bypassed, the Oracle database server is unaware of the commit in the non-Oracle system. Consequently, the data at the non-Oracle system can be committed while the transaction in the Oracle database server is not.
If the transaction in the Oracle database server is rolled back, data inconsistencies between the Oracle database server and the non-Oracle server can occur. This situation results in global data inconsistency.
Note that if the application executes a regular COMMIT statement, the Oracle database server can coordinate the distributed transaction with the non-Oracle system. The statement executed with the pass-through facility is part of the distributed transaction.
The table below shows the functions and procedures provided by the DBMS_HS_PASSTHROUGH package that allow you to execute pass-through SQL statements.
Non-queries include the following statements and types of statements:
To execute non-query statements, use the EXECUTE_IMMEDIATE function. For example, to execute a DDL statement at a non-Oracle system that you can access using the database link SalesDB, execute:
DECLARE num_rows INTEGER; BEGIN num_rows := DBMS_HS_PASSTHROUGH.EXECUTE_IMMEDIATE@SalesDB ('CREATE TABLE DEPT (n SMALLINT, loc CHARACTER(10))'); END;
The variable num_rows is assigned the number of rows affected by the execution. For DDL statements, zero is returned. Note that you cannot execute a query with EXECUTE_IMMEDIATE and you cannot use bind variables.
Bind variables allow you to use the same SQL statement multiple times with different values, reducing the number of times a SQL statement needs to be parsed. For example, when you need to insert four rows in a particular table, you can parse the SQL statement once and bind and execute the SQL statement for each row. One SQL statement can have zero or more bind variables.
To execute pass-through SQL statements with bind variables, you must:
Figure 3-1 shows the flow diagram for executing non-queries with bind variables.
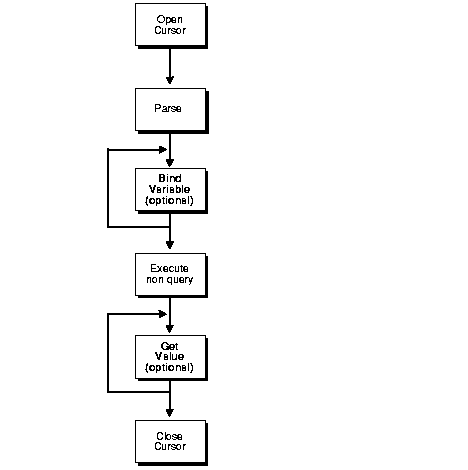
The syntax of the non-Oracle system determines how a statement specifies a bind variable. For example, in Oracle you define bind variables with a preceding colon, as in:
UPDATE EMP SET SAL=SAL*1.1 WHERE ENAME=:ename
In this statement, ename is the bind variable. In other non-Oracle systems you may need to specify bind variables with a question mark, as in:
UPDATE EMP SET SAL=SAL*1.1 WHERE ENAME= ?
In the bind variable step, you must positionally associate host program variables (in this case, PL/SQL) with each of these bind variables.
For example, to execute the above statement, you can use the following PL/SQL program:
DECLARE c INTEGER; nr INTEGER; BEGIN c := DBMS_HS_PASSTHROUGH.OPEN_CURSOR@SalesDB; DBMS_HS_PASSTHROUGH.PARSE@SalesDB(c, 'UPDATE EMP SET SAL=SAL*1.1 WHERE ENAME=?'); DBMS_HS_PASSTHROUGH.BIND_VARIABLE(c,1,'JONES'); nr:=DBMS_HS_PASSTHROUGH.EXECUTE_NON_QUERY@SalesDB(c); DBMS_OUTPUT.PUT_LINE(nr||' rows updated'); DBMS_HS_PASSTHROUGH.CLOSE_CURSOR@salesDB(c); END;
In some cases, the non-Oracle system can also support OUT bind variables. With OUT bind variables, the value of the bind variable is not known until after the execution of the SQL statement.
Although OUT bind variables are populated after the SQL statement is executed, the non-Oracle system must know that the particular bind variable is an OUT bind variable before the SQL statement is executed. You must use the BIND_OUT_VARIABLE procedure to specify that the bind variable is an OUT bind variable.
After the SQL statement is executed, you can retrieve the value of the OUT bind variable using the GET_VALUE procedure.
A bind variable can be both an IN and an OUT variable. This means that the value of the bind variable must be known before the SQL statement is executed but can be changed after the SQL statement is executed.
For IN OUT bind variables, you must use the BIND_INOUT_VARIABLE procedure to provide a value before the SQL statement is executed. After the SQL statement is executed, you must use the GET_VALUE procedure to retrieve the new value of the bind variable.
The difference between queries and non-queries is that queries retrieve a result set from a SELECT statement. The result set is retrieved by iterating over a cursor.
Figure 3-2 illustrates the steps in a pass-through SQL query. After the system parses the SELECT statement, each row of the result set can be fetched with the FETCH_ROW procedure. After the row is fetched, use the GET_VALUE procedure to retrieve the select list items into program variables. After all rows are fetched you can close the cursor.
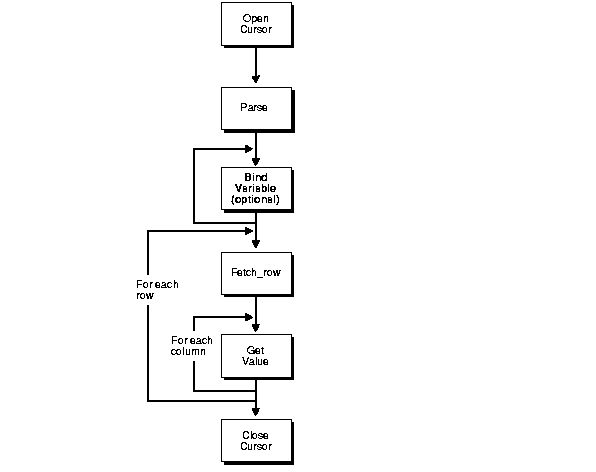
You do not have to fetch all the rows. You can close the cursor at any time after opening the cursor, for example, after fetching a few rows.
The next example executes a query:
DECLARE val VARCHAR2(100); c INTEGER; nr INTEGER; BEGIN c := DBMS_HS_PASSTHROUGH.OPEN_CURSOR@SalesDB; DBMS_HS_PASSTHROUGH.PARSE@SalesDB(c, 'select ename from emp where deptno=10'); LOOP nr := DBMS_HS_PASSTHROUGH.FETCH_ROW@SalesDB(c); EXIT WHEN nr = 0; DBMS_HS_PASSTHROUGH.GET_VALUE@SalesDB(c, 1, val); DBMS_OUTPUT.PUT_LINE(val); END LOOP; DBMS_HS_PASSTHROUGH.CLOSE_CURSOR@SalesDB(c); END;
After parsing the SELECT statement, the rows are fetched and printed in a loop until the function FETCH_ROW returns the value 0.
Various relational databases allow stored procedures to return result sets. In other words, stored procedures will be able to return one or more sets of rows. This is a relatively new feature for any database.
Traditionally, database stored procedures worked exactly like procedures in any high-level programming language. They had a fixed number of arguments which could be of types in, out, or in-out. If a procedure had n arguments, it could return at most n values as results. However, suppose that somebody wanted a stored procedure to execute a query such as SELECT * FROM emp and return the results. The emp table might have a fixed number of columns but there is no way of telling, at procedure creation time, the number of rows it has. Because of this, no traditional stored procedure can be created that can return the results of a such a query. As a result, several relational database vendors added the capability of returning results sets from stored procedures, but each kind of relational database returns result sets from stored procedures in a different way.
Oracle has a data type called a REF CURSOR. Like every other Oracle data type, a stored procedure can take this data type as an in or out argument. In Oracle, a stored procedure can return a result set in the following way. To return a result set, a stored procedure must have an output argument of type REF CURSOR. It then opens a cursor for a SQL statement and places a handle to that cursor in that output parameter. The caller can then fetch from the REF CURSOR the same way as from any other cursor.
Oracle can do a lot more than simply return result sets. REF CURSORs can be passed as input arguments to PL/SQL routines to be passed back and forth between client programs and PL/SQL routines or between several PL/SQL routines. Until recently, REF CURSORs in Oracle did not work in a distributed environment. This meant that you could pass REF CURSOR values between PL/SQL routines in the same database or between a client program and a PL/SQL routine, but they could not be passed from one database to another. As of Oracle9i, that restriction has been removed in the case of Heterogeneous Services.
Several non-Oracle systems allow stored procedures to return result sets but do so in completely different ways. No other relational database management system (RDBMS) has anything like the Oracle REF CURSOR data type. Result sets are supported to some extend in DB2, Sybase, Microsoft SQL Server, and Informix. Result set support in these databases is based on one of the following two models.
When creating a stored procedure, the user can explicitly specify the maximum number of result sets that can be returned by that stored procedure. While executing, the stored procedure can open anywhere from zero to its pre-specified maximum number of result sets. After the execution of the stored procedure, a client program can obtain handles to these result sets by using either an embedded SQL directive or calling a client library function. After that the client program can fetch from the result in the same way as from a regular cursor.
In this model, there is no pre-specified limit to the number of result sets that can be returned by a stored procedure. Both Model 1 and Oracle have a limit. For Oracle the number of result sets returned by a stored procedure can be at most the number of REF CURSOR out arguments; for Model 1, the upper limit is specified using a directive in the stored procedure language. Another way that Model 2 differs from Oracle and Model 1 is that they do not return a handle to the result sets but instead place the entire result set on the wire when returning from a stored procedure. For Oracle, the handle is the REF CURSOR out argument; for Model 1, it is obtained separately after the execution of the stored procedure. For both Oracle and Model 1, once the handle is obtained, data from the result set is obtained by doing a fetch on the handle; we have a bunch of cursors open and can fetch in any order. In the case of Model 2, however, all the data is already on the wire, with the result sets coming in the order determined by the stored procedure and the output arguments of the procedures coming at the end. So the whole of the first result set must be fetched, then the whole of the second one, until all of the results have been fetched. Finally, the stored procedure out arguments must be fetched.
As can be seen in the preceding sections, result set support exists among non-Oracle databases in a variety of forms. All of these have to be mapped onto the Oracle REF CURSOR model. Due to the considerable differences in behavior among the various non-Oracle systems, Heterogeneous Services result set support will have to behave in one of two different ways depending on the non-Oracle system it is connected to.
Please note the following about Heterogeneous Services result set support:
REF CURSOR out arguments from stored procedures. In and in-out arguments will not be supported.REF CURSOR out arguments will all be anonymous REF CURSORs. No typed REF CURSORs are returned by Heterogeneous Services.Oracle generally behaves such that each result set returned by the non-Oracle system stored procedure is mapped by the driver to an out argument of type REF CURSOR. The client program sees a stored procedure with several out arguments of type REF CURSOR. After executing the stored procedure, the client program can fetch from the REF CURSOR in exactly the same way as it would from a REF CURSOR returned by an Oracle stored procedure. When connecting to the gateway as described in Model 1, Heterogeneous Services will be in cursor mode.
In Oracle, there is a pre-specified maximum number of result sets that a particular stored procedure can return. The number of result sets returned is at most the number of REF CURSOR out arguments for the stored procedure. It can, of course, return fewer result sets, but it can never return more.
For the system described in Model 2, there is no pre-specified maximum of result sets that can be returned. In the case of Model 1, we know the maximum number of result sets that a procedure can return, and the driver can return to Heterogeneous Services a description of a stored procedure with that many REF CURSOR out arguments. If, on execution of the stored procedure, fewer result sets than the maximum are returned, then the other REF CURSOR out arguments will be set to NULL.
Another problem for Model 2 database servers is that result sets have to be retrieved in the order in which they were placed on the wire by the database. This prevents Heterogeneous Services from running in cursor mode when connecting to these databases. To access result sets returned by these stored procedures, you must operate Heterogeneous Services in sequential mode.
In sequential mode, the procedure description returned by the driver contains the following:
out argument of type REF CURSOR (corresponding to the first result set returned by the stored procedure)The client fetches from this REF CURSOR and then calls the virtual package function dbms_hs_result_set.get_next_result_set to get the REF CURSOR corresponding to the next result set. This function call is repeated until all result sets have been fetched. The last result set returned will actually be the out arguments of the remote stored procedure.
The major limitations of sequential mode are as follows:
All examples in this section use the following non-Oracle system stored procedure.
create or replace package rcpackage is type rctype is ref cursor; end rcpackage; / create or replace procedure refcurproc (arg1 in varchar2, arg2 out varchar2, rc1 out rcpackage.rctype, rc2 out rcpackage.rctype) is begin arg2 := arg1; open rc1 for select * from emp; open rc2 for select * from dept; end; /
This stored procedure assigns the input parameter arg1 to the output parameter arg2, opens the query SELECT * FROM emp in REF CURSOR rc1, and opens the query SELECT * FROM dept in REF CURSOR rc2.
The following example shows OCI program fetching from result sets in cursor mode.
OCIEnv *ENVH; OCISvcCtx *SVCH; OCIStmt *STMH; OCIError *ERRH; OCIBind *BNDH[4]; OraText arg1[20]; OraText arg2[20]; OCIResult *arg3, *arg4; OCIStmt *rstmt1, *rstmt2; ub2 rcode[4]; ub2 rlens[4]; sb2 inds[4]; OraText *stmt = (OraText *) "begin refcurproc@link(:1,:2,:3,:4); end;"; /* Handle Initialization code skipped */ /* Prepare procedure call statement */ OCIStmtPrepare(STMH, ERRH, stmt, strlen(stmt), OCI_NTV_SYNTAX, OCI_DEFAULT); /* Bind procedure arguments */ inds[0] = 0; strcpy((char *) arg1, "Hello World"); rlens[0] = strlen(arg1); OCIBindByPos(STMH, &BNDH[0], ERRH, 1, (dvoid *) arg1, 20, SQLT_CHR, (dvoid *) &(inds[0]), &(rlens[0]), &(rcode[0]), 0, (ub4 *) 0, OCI_DEFAULT); inds[1] = 0; rlens[1] = 0; OCIBindByPos(STMH, &BNDH[1], ERRH, 2, (dvoid *) arg2, 20, SQLT_CHR, (dvoid *) &(inds[1]), &(rlens[1]), &(rcode[1]), 0, (ub4 *) 0, OCI_DEFAULT); inds[2] = 0; rlens[2] = 0; OCIDescriptorAlloc(ENVH, (dvoid **) &arg3, OCI_DTYPE_RSET, 0, (dvoid **) 0); OCIBindByPos(STMH, &BNDH[2], ERRH, 3, (dvoid *) arg3, 0, SQLT_RSET, (dvoid *) &(inds[2]), &(rlens[2]), &(rcode[2]), 0, (ub4 *) 0, OCI_DEFAULT); inds[3] = 0; rlens[3] = 0; OCIDescriptorAlloc(ENVH, (dvoid **) &arg4, OCI_DTYPE_RSET, 0, (dvoid **) 0); OCIBindByPos(STMH, &BNDH[3], ERRH, 4, (dvoid *) arg4, 0, SQLT_RSET, (dvoid *) &(inds[3]), &(rlens[3]), &(rcode[3]), 0, (ub4 *) 0, OCI_DEFAULT); /* Execute procedure */ OCIStmtExecute(SVCH, STMH, ERRH, 1, 0, (CONST OCISnapshot *) 0, (OCISnapshot *) 0, OCI_DEFAULT); /* Convert result set descriptors to statement handles */ OCIResultSetToStmt(arg3, ERRH); OCIResultSetToStmt(arg4, ERRH); rstmt1 = (OCIStmt *) arg3; rstmt2 = (OCIStmt *) arg4; /* After this the user can fetch from rstmt1 and rstmt2 */
The following example shows OCI program fetching from result sets in sequential mode.
OCIEnv *ENVH; OCISvcCtx *SVCH; OCIStmt *STMH; OCIError *ERRH; OCIBind *BNDH[2]; OraText arg1[20]; OCIResult *rset; OCIStmt *rstmt; ub2 rcode[2]; ub2 rlens[2]; sb2 inds[2]; OraText *stmt = (OraText *) "begin refcurproc@link(:1,:2); end;"; OraText *n_rs_stm = (OraText *) "begin :ret := DBMS_HS_RESULT_SET.GET_NEXT_RESULT_SET@link; end;"; /* Prepare procedure call statement */ /* Handle Initialization code skipped */ OCIStmtPrepare(STMH, ERRH, stmt, strlen(stmt), OCI_NTV_SYNTAX, OCI_DEFAULT); /* Bind procedure arguments */ inds[0] = 0; strcpy((char *) arg1, "Hello World"); rlens[0] = strlen(arg1); OCIBindByPos(STMH, &BNDH[0], ERRH, 1, (dvoid *) arg1, 20, SQLT_CHR, (dvoid *) &(inds[0]), &(rlens[0]), &(rcode[0]), 0, (ub4 *) 0, OCI_DEFAULT); inds[1] = 0; rlens[1] = 0; OCIDescriptorAlloc(ENVH, (dvoid **) &rset, OCI_DTYPE_RSET, 0, (dvoid **) 0); OCIBindByPos(STMH, &BNDH[1], ERRH, 2, (dvoid *) rset, 0, SQLT_RSET, (dvoid *) &(inds[1]), &(rlens[1]), &(rcode[1]), 0, (ub4 *) 0, OCI_DEFAULT); /* Execute procedure */ OCIStmtExecute(SVCH, STMH, ERRH, 1, 0, (CONST OCISnapshot *) 0, (OCISnapshot *) 0, OCI_DEFAULT); /* Convert result set to statement handle */ OCIResultSetToStmt(rset, ERRH); rstmt = (OCIStmt *) rset; /* After this the user can fetch from rstmt */ /* Issue get_next_result_set call to get handle to next_result set */ /* Prepare Get next result set procedure call */ OCIStmtPrepare(STMH, ERRH, n_rs_stm, strlen(n_rs_stm), OCI_NTV_SYNTAX, OCI_DEFAULT); /* Bind return value */ OCIBindByPos(STMH, &BNDH[1], ERRH, 1, (dvoid *) rset, 0, SQLT_RSET, (dvoid *) &(inds[1]), &(rlens[1]), &(rcode[1]), 0, (ub4 *) 0, OCI_DEFAULT); /* Execute statement to get next result set*/ OCIStmtExecute(SVCH, STMH, ERRH, 1, 0, (CONST OCISnapshot *) 0, (OCISnapshot *) 0, OCI_DEFAULT); /* Convert next result set to statement handle */ OCIResultSetToStmt(rset, ERRH); rstmt = (OCIStmt *) rset; /* Now rstmt will point to the second result set returned by the remote stored procedure */ /* Repeat execution of get_next_result_set to get the output arguments */
Assume that the table loc_emp is a local table exactly like the remote emp table. The same assumption applies for loc_dept.
declare rc1 rcpackage.rctype; rec1 loc_emp%rowtype; rc2 rcpackage.rctype; rec2 loc_dept%rowtype; arg2 varchar2(20); begin -- Execute procedure refcurproc@link('Hello World', arg2, rc1, rc2); -- Fetch 20 rows from the remote emp table and insert them -- into loc_emp for i in 1 .. 20 loop fetch rc1 into rec1; insert into loc_emp (rec1.empno, rec1.ename, rec1.job, rec1.mgr, rec1.hiredate, rec1.sal, rec1.comm, rec1.deptno); end loop; -- Close the ref cursor close rc1; -- Fetch 5 rows from the remote dept table and insert them -- into loc_dept for i in 1 .. 5 loop fetch rc2 into rec2; insert into loc_dept values (rec2.deptno, rec2.dname, rec2.loc); end loop; -- Close the ref cursor close rc2; end;
The tables loc_emp and loc_dept are same as above. The table outarguments contains columns corresponding to the out arguments of the remote stored procedure
declare rc1 rcpackage.rctype; rec1 loc_emp%rowtype; rc2 rcpackage.rctype; rec2 loc_dept%rowtype; rc3 rcpackage.rctype; rec3 outargs%rowtype; begin -- Execute procedure refcurproc@link('Hello World', rc1); -- Fetch 20 rows from the remote emp table and insert them -- into loc_emp for i in 1 .. 20 loop fetch rc1 into rec1; insert into loc_emp (rec1.empno, rec1.ename, rec1.job, rec1.mgr, rec1.hiredate, rec1.sal, rec1.comm, rec1.deptno); end loop; -- Close ref cursor close rc1; -- Get the next result set returned by the stored procedure rc2 := dbms_hs_result_set.get_next_result_set@link; -- Fetch 5 rows from the remote dept table and insert them -- into loc_dept for i in 1 .. 5 loop fetch rc2 into rec2; insert into loc_dept values (rec2.deptno, rec2.dname, rec2.loc); end loop; --Close ref cursor close rc2; -- Get the output arguments from the remote stored procedure -- Since we are in sequential mode, they will be returned in the -- form of a result set rc3 := dbms_hs_result_set.get_next_result_set@link; --Fetch them and insert them into the outarguments table fetch rc3 into rec3; insert into outarguments (rec3.col); --Close ref cursor close rc3; end;
Most database systems have some form of data dictionary. A data dictionary is a collection of information about the database objects that have been created by various users of the system. For a relational database, a data dictionary is a set of tables and views which contain information about the data in the database. This information includes information on the users who are using the system and on the objects that they have created (such as tables, views, triggers and so forth). For the most part, all data dictionaries (regardless of the database system) contain the same information but each database system organizes the information in a different way.
For example, the ALL_CATLOG Oracle data dictionary view gives a list of tables, views, and sequences in the database. It has three columns: the first is called OWNER and is the name of the owner of the object, the second is called TABLE_NAME and is the name of the object, and the third is called TABLE_TYPE and is the type. This field has value TABLE, VIEW, SEQUENCE and so forth depending on the object type. However, in Sybase, the same information is stored in two tables called sysusers and sysobjects whose column names are quite different than those of Oracle ALL_CATALOG table. Additionally, in Oracle, the table type is a string with value TABLE, VIEW and so forth but in Sybase it is a letter. For example, in Sybase, U means user table, S means system table, V means view, and so forth.
If the client program wanted information from the table ALL_CATALOG at Sybase then all it would have to do is to send a query referencing ALL_CATALOG@database link to a gateway and Heterogeneous Services will translate this query to the appropriate one on systables and send the translated query to Sybase.
SELECT SU."name" OWNER, SO."name" TABLE_NAME, DECODE(SO."type", 'U ','TABLE', 'S ', 'TABLE', 'V ', 'VIEW') TABLE_TYPE FROM "dbo"."sysusers"@link SU, "dbo"."sysobjects"@link SO WHERE SU."uid" = SO."uid" AND (SO."type" = 'V' OR SO."type" = 'S' OR SO."type" = 'U')>
To relay such a translation of a query on an Oracle data dictionary table to the equivalent one on the non-Oracle system data dictionary table, Heterogeneous Services needs data dictionary translations for that non-Oracle system. A data dictionary translation is a view definition (essentially a select statement) over one or more non-Oracle system data dictionary tables such that the view looks exactly like the Oracle data dictionary table, with the same column names and the same information formatting. A data dictionary translation need not be as simple as the one above. Often the information needed is not found in one or two tables but is scattered over many tables and the data dictionary translation is a complex join over those tables.
In some cases, an Oracle data dictionary table does not have a translation because the information needed does not exist at the non-Oracle system. In such cases, the gateway can decide not to upload a translation at all or can resort to an alternative approach called mimicking. If the gateway wants to mimic a data dictionary table then it will let Heterogeneous Services know and Heterogeneous Services will obtain the description of the data dictionary table by querying the local database but when asked to fetch data, it will report that no rows were selected.
The examples given below show the output of some data dictionary queries sent to Informix, and they compare the results with those produced when querying the same view on Oracle.
To check the current session's user name on Oracle and on Informix, enter the following:
SQL> SELECT a.USERNAME, b.USERNAME FROM USER_USERS a, USER_USERS@remote_db b; USERNAME USERNAME ------------------------------ ------------------------------ THSU thsu
To check the current session's user ID on Oracle and on Informix, enter the following:
SQL> SELECT a.USER_ID, b.USER_ID FROM USER_USERS a, USER_USERS@remote_db b; USER_ID USER_ID ---------- ---------- 25 0
To check constraints defined on a non-Oracle system for tables owned by an arbitrary user, enter the following:
SQL SELECT CONSTRAINT_NAME, TABLE_NAME FROM ALL_CONSTRAINTS@remote_db 2 WHERE OWNER = 'thsu'; CONSTRAINT_NAME TABLE_NAME ------------------------------ ------------------------------ u19942_5270 thsmv_order_line u24612_7116 thsmv_customer u24613_7117 thsmv_orders
|
Note: Informix uses a different form of constraint names than Oracle, and its data dictionary maintains the table names in lowercase instead of uppercase. |
| See Also:
Appendix D, "Data Dictionary Translation Support" for more information on data dictionary translations |
Oracle has five datetime data types:
Heterogeneous Services generic code supports Oracle datetime data types in SQL and stored procedures. Oracle does not support these data types in data dictionary translations or queries involving data dictionary translations.
Even though Heterogeneous Services generic code supports this, support for a particular gateway depends on whether or not the driver for that non-Oracle system has implemented datetime support. Support even when the driver implements it may be partial because of the limitations of the non-Oracle system. Users should consult the documentation for their particular gateway on this issue.
The user must set the timestamp formats of the non-Oracle system in the gateway initialization file. The parameters to set are HS_NLS_TIMESTAMP_FORMAT and HS_NLS_TIMESTAMP_TZ_FORMAT. The user should also set the local time zone for the non-Oracle system in the initialization file. Parameter to set is HS_TIME_ZONE.
| See Also:
Oracle9i SQL Reference for information on datetime data types |
Heterogeneous Services provides the infrastructure for the implementation of the two-phase commit mechanism. The extent to which this is supported depends on the gateway, and the remote system. Please refer to individual gateway manuals for more information.
| See Also:
Oracle9i Administrator's Guide for more information about the two-phase commit protocol |
Earlier versions of gateways had limited support for the LONG data type. LONG is an Oracle data type that can be used to store up to 2 gigabytes (GB) of character/raw data (LONG RAW). These earlier versions restricted the amount of LONG data to 4 MB. This was because they would treat LONG data as a single piece. This led to restrictions of memory and network bandwidth on the size of the data that could be handled. Current gateways have extended the functionality to support the full 2 GB of heterogeneous LONG data. They handle the data piecewise between the agent and the Oracle server, thereby doing away with the large memory and network bandwidth requirements.
There is a new Heterogeneous Services initialization parameter, HS_LONG_PIECE_TRANSFER_SIZE, that can be used to set the size of the transferred pieces. For example, let us consider fetching 2 GB of LONG data from a heterogeneous source. A smaller piece size means less memory requirement, but more round trips to fetch all the data. A larger piece size means fewer round trips, but more of a memory requirement to store the intermediate pieces internally. Thus, the initialization parameter can be used to tune a system for the best performance, that is, for the best trade-off between round-trips and memory requirements. If the initialization parameter is not set, the system defaults to a piece size of 64 KB.
Until Oracle9i, you could not describe non-Oracle system objects using the SQL*Plus DESCRIBE command. As of Oracle9i, functionality to do this has been added to Heterogeneous Services. There are still some limitations. For instance, using Heterogeneous links, you still cannot describe packages, sequences, synonyms, or types.
The SQL*Plus DESCRIBE command is implemented using the OCIDescribeAny call, which was likewise unavailable before Oracle9i. The OCIDescribeAny call can also describe databases and schemas, which you cannot do through the SQL*Plus DESCRIBE command. With Heterogeneous Services, you can do both.
In order to implement this functionality some additional driver logic is needed; not all drivers may have implemented it. Please consult individual gateway documentation to see if this feature is supported in that gateway.
This section explains some of the constraints that exist on SQL in a distributed environment. These constraints apply to distributed environments that involve access to non-Oracle systems or remote Oracle databases.
This section contains the following topics:
|
Note: Many of the rules for Heterogeneous access also apply to remote references. For more information, please see the distributed database section of the Oracle9i Database Administrator's Guide. |
A statement can, with restrictions, be executed on any database node referenced in the statement or the local node. If all objects referenced are resolved to a single, referenced node, then Oracle will attempt to execute a query at that node. You can force execution at a referenced node by using the /*+ REMOTE_MAPPED */ or /*+ DRIVING_SITE */ hints. If a statement is forwarded to a different node than the node it was issued at, then the statement is said to be remote mapped.
The ways in which statements can, must, and cannot be remote mapped are subject to specific rules or restrictions. If these rules are not all followed, then an error will occur. As long as the statements issued are consistent with all these rules, the order in which the rules are applied does not matter.
Different constraints exist when you are using SQL for remote mapping in a distributed environment. This distributed environment can include remote Oracle databases as well as databases that involve Oracle Transparent Gateways or Generic Connectivity connections between Oracle and non-Oracle systems.
The following section lists some of the different constraints that exist when you are using SQL for remote mapping in a distributed environment.
|
Note: In the examples that follow, |
In Oracle data definition language, the target object syntactically has no place for a remote reference. Data definition language statements that contain remote references are always executed locally. For Heterogeneous Services, this means it cannot directly create database objects in a non-Oracle database using SQL.
However, there is an indirect way using pass-through SQL.
Consider the following example:
BEGIN DBMS_HS.PASSTHROUGHSQL.EXECUTE_IMMEDIATE@remote_db ( 'create table x1 (c1 char, c2 number)' ); END;
This rule is more restrictive for non-Oracle remote databases than for a remote Oracle database. This is because the remote system cannot fetch data from the originating Oracle database while executing DML statements targeting tables in a non-Oracle system.
For example, to insert all local employees from the local emp1 table to a remote Oracle emp2 table, use the following statement:
INSERT INTO emp2@remote_oracle_db SELECT * FROM emp1;
This statement is remote mapped to the remote database. The remote mapped statement sent to the remote database contains a remote reference back to the originating database for emp1. Such a remote link received by the remote database is called a callback link.
In general however, gateways callback links are not supported. When you try to insert into a non-Oracle system using a select statement referencing a local table, an error occurs.
For example, consider the following statement:
INSERT INTO emp2@remote_db SELECT * FROM emp1;
The statement returns the following error message:
ORA-02025: all tables in the SQL statement must be at the remote database
The work around is to write a PL/SQL block:
DECLARE CURSOR remote_insert IS SELECT * FROM emp2; BEGIN FOR rec IN remote_insert LOOP INSERT INTO emp1@remote_db (empno, ename, deptno) VALUES ( rec.empno, rec.ename, rec.deptno ); END loop; END; /
Another special case involves session specific SQL functions such as USER, USERENV and SYSDATE. These functions may need to be executed at the originating site. A remote mapped statement containing these functions will contain a callback link. For a non-Oracle database where callbacks are not supported this could (by default) result in a restriction error.
For example, consider the following statement:
DELETE FROM emp1@remote_db WHERE hiredate > sysdate;
The statement returns the following error message:
ORA-02070: database REMOTE_DB does not support special functions in this context
This often must be resolved by replacing special functions with a bind variable:
DELETE FROM emp1@remote_db WHERE hiredate > :1;
Currently, the above column types are not supported for heterogeneous access. Hence, this limitation is not directly encountered.
Note that in our description of Rule B we already encountered special constructs such as callback links and special functions as examples of this.
If the statement is a select (or dml with the target table local) and none of the remaining rules would require the statement to be remote mapped the statement can still be executed by processing the query locally using the local SQL engine and the remote select operation.
The remote select operation is the operation to retrieve rows for remote table data as opposed to other operations like full table scan and index access which retrieve rows of local table data. The remote table scan has a SQL statement associated with the operation. A full table scan of table emp1 is issued as SELECT * FROM emp1 (with the * expanded to the full column list). Access for indexes is converted back to where clause predicates and also filters that can be supported are passed down to the WHERE clause of the remote row source.
You can check the SQL statement generated by the Oracle server by explaining the statement and querying the OTHER column of the explain plan table for each REMOTE operation.
| See Also:
Example of Using Index and Table Statistics for more information on how to interpret explain plans with remote references |
For example consider the following statement:
SELECT COUNT(*) FROM emp1@remote_db WHERE hiredate < sysdate;
The statement returns the following output:
COUNT(*) ---------- 14 1 row selected.
The remote table scan is:
SELECT hiredate FROM emp1
Since the predicate converted to a filter cannot be generated back and passed down to the remote operation because sysdate is not supported by the remote_db or evaluation rules, sysdate must be executed locally.
This limitation is not directly encountered since table expressions are not supported in the heterogeneous access module.
For example, consider the following statement:
SELECT long1 FROM table_with_long@remote_db, dual;
The statement returns the following error message:
ORA-02025: all tables in the SQL statement must be at the remote database
This can be resolved by the following statement:
SELECT long1 FROM table_with_long@remote_db WHERE long_idx = 1;
When the SQL statement is of the form SELECT...FOR UPDATE OF..., the statement must be mapped to the node on which the table or tables with columns referenced in the FOR UPDATE OF clause resides.
For example, consider the following statement:
SELECT ename FROM emp1@remote_db WHERE hiredate < sysdate FOR UPDATE OF empno
The statement returns the following error message:
ORA-02070: database REMOTE_DB does not support special functions in this context
This rule is not encountered for the heterogeneous access since remote non-Oracle sequences are not supported. The restriction for remote non-Oracle access is already present because of the callback link restriction.
This rule is also already covered under the callback link restriction discussed in Rule B.
The work around for this restriction is to use unique bind variables and bind by number.
As discussed in the previous section, updates to remote non-Oracle objects through an Oracle server are restricted by the missing callback feature support present in the Oracle database. This restricts data manipulation language (DML) upon remote non-Oracle database objects to statements that reference all objects in that remote non-Oracle database or are literals or bind variables.
Because of this, no objects can be referenced from the originating Oracle server or other remote objects.
Also, as with any remote update, whether non-Oracle or a previous remote update, if a SQL update in an Oracle format is not supported, then an error is returned in the following format:
ORA-2070: database ... does not support ... in this context.
|
Note: These restrictions do not apply to DML with a local target object referencing non-Oracle or remote Oracle database objects. |
You can perform DML to remote Oracle or non-Oracle target tables in an Oracle format that is not supported by using PL/SQL. Declare a cursor that selects the appropriate row and executes the update for each row selected. The row may need to be unique, identified by selecting a primary key, or, if not available, a rowid.
Consider the following example:
DECLARE CURSOR c1 IS SELECT empno FROM emp e, dept d WHERE e.deptno = d.deptno AND d.dname = 'SALES'; BEGIN FOR REC IN c1 LOOP UPDATE emp1@remote_db SET comm = .1 * sal; WHERE empno = rec.empno; END loop; END; /
Oracle's optimizer can be used with Heterogeneous Services. Heterogeneous Services collects certain table and index statistics information on the respective non-Oracle system tables and passes this information back to the Oracle server. The Oracle cost based optimizer uses this information when building the query plan.
There are several other optimizations that the cost based optimizer performs. The most important ones are remote sort elimination and remote joins.
Consider the following statement where you create a table in the Oracle database with 10 rows:
CREATE table_T1 (C1 number);
Analyze the table by issuing the following SQL statement:
ANALYZE table_T1 COMPUTE STATISTICS;
Now create a table in the non-Oracle system with 1000 rows:
CREATE TABLE remote_t1 (C1 number)
Issue the following SQL statement:
SELECT a.* FROM remote_t1@remote_db a, T1 b WHERE a.C1 = b.C1
The Oracle optimizer issues the following SQL statement to the agent:
SELECT C1 FROM remote_t1
This fetches all the 1000 rows from the non-Oracle system and performs the join in the Oracle database.
Now, if we add a unique index on the column C1 in the table remote_t1, and issue the same SQL statement again, the agent receives the following SQL statement:
SELECT C1 FROM remote_t1 WHERE C1 = ?
for each value of C1 in the local t1.
|
Note: (' |
To verify the SQL execution plan, generate an explain plan for the SQL statement. Load utlxplan in the admin directory first.
At the command prompt, type:
EXPLAIN PLAN FOR SELECT a.* FROM remote_t1@remote_db a, T1 b WHERE a.C1 = b.C1;
Then, run the utlxpls utility script by entering the following statement.
@utlxpls
The operation remote indicates that remote SQL is being referenced.
To find out what statement is sent, type the following statement at the command prompt:
SELECT ID, OTHER FROM EXPLAIN_PLAN WHERE OPERATION = 'REMOTE';
The following is an example of the remote join optimization capability of the Oracle database.
Consider the following example:
EXPLAIN PLAN FOR SELECT e.ename, d.dname, f.ename, f.deptno FROM dept d, emp@remote_db e, emp@remote_db f WHERE e.mgr = f.empno AND e.deptno = d.deptno AND e.empno = f.empno; @utlxpls
| Operation | Name | Rows | Bytes | Cost | Pstar |
|---|---|---|---|---|---|
|
SELECT STATEMENT |
- |
1 |
101 |
128 |
- |
|
HASH JOIN |
- |
2K |
132K |
19 |
- |
|
TABLE ACCESS FULL |
DEPT |
21 |
462 |
1 |
- |
|
REMOTE |
- |
2K |
89K |
16 |
- |
Issue the following statement:
SET longwidth 300 SELECT other FROM plan_table WHERE operation = 'REMOTE';
You get the following output:
SELECT A1."ENAME",A1."MGR",A1."DEPTNO",A1."EMPNO",A2."ENAME",A2."DEPTNO",A2."EMPNO",A2. "EMPNO" FROM "EMP" A1,"EMP" A2 WHERE A1."EMPNO"=A2."EMPNO" AND A1."MGR"=A2."EMPNO"
For instance, the earlier example can be rewritten to the form:
SELECT v.ename, d.dname, d.deptno FROM dept d, (SELECT /*+ NO_MERGE */ e.deptno deptno, e.ename ename emp@remote_db e, emp@remote_db f WHERE e.mgr = f.empno AND e.empno = f.empno; ) WHERE v.deptno = d.deptno;
This guarantees a remote join because it has been isolated in a nested query with the NO_MERGE hint.
|
 Copyright © 2001, 2002 Oracle Corporation. All Rights Reserved. |
|

