Symmetric or Active/Active Configuration
In a symmetric configuration, each server is configured to run a specific application or service and provide redundancy for its peer. In the example below, each server is running one application service group. When a failure occurs, the surviving server hosts both application groups.

Click the thumbnail above to view full-sized image.
Symmetric Failover
Symmetric configurations appear more efficient in terms of hardware utilization. In the asymmetric example, the redundant server requires only as much processor power as its peer. On failover, performance remains the same. In the symmetric example, the redundant server requires not only enough processor power to run the existing application, but also enough to run the new application it takes over.
Further issues can arise in symmetric configurations when multiple applications running on the same system do not co-exist properly. Some applications work well with multiple copies started on the same system, but others fail. Issues can also arise when two applications with different I/O and memory requirements run on the same system.
N-to-1 Configuration
An N-to-1 failover configuration reduces the cost of hardware redundancy and still provides a potential, dedicated spare. In an asymmetric configuration there is no performance penalty and there are no issues with multiple applications running on the same system; however, the drawback is the 100 percent redundancy cost at the server level.
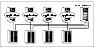
Click the thumbnail above to view full-sized image.
N-to-1 Configuration
An N-to-1 configuration is based on the concept that multiple, simultaneous server failures are unlikely; therefore, a single redundant server can protect multiple active servers. When a server fails, its applications move to the redundant server. For example, in a 4-to-1 configuration, one server can protect four servers, which reduces redundancy cost at the server level from 100 percent to 25 percent. In this configuration, a dedicated, redundant server is cabled to all storage and acts as a spare when a failure occurs.
The problem with this design is the issue of failback. When the original, failed server is repaired, all services normally hosted on the server must be failed back to free the spare server and restore redundancy to the cluster.
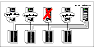
Click the thumbnail above to view full-sized image.
N-to-1 Failover Requiring Failback
Most shortcomings of early N-to-1 cluster configurations were caused by the limitations of storage architecture. Typically, it was impossible to connect more than two hosts to a storage array without complex cabling schemes and their inherent reliability problems, or resorting to expensive arrays with multiple controller ports.
|