Cluster Membership
Cluster membership implies that the cluster must accurately determine which nodes are active in the cluster at any given time. In order to take corrective action on node failure, surviving nodes must agree on when a node has departed. This membership needs to be accurate and must be coordinated among active members. This becomes critical considering nodes can be added, rebooted, powered off, faulted, and so on. VCS uses its cluster membership capability to dynamically track the overall cluster topology. Cluster membership is maintained through the use of heartbeats.
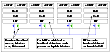
LLT is responsible for sending and receiving heartbeat traffic over network links. Each node sends heartbeat packets on all configured LLT interfaces. By using an LLT ARP response, each node sends a single packet that tells all other nodes it is alive, as well as the communications information necessary for other nodes to send unicast messages back to the broadcaster.
LLT can be configured to designate specific links as high priority and others as low priority. High priority links are used for cluster communications (GAB) as well as heartbeat. Low priority links only carry heartbeat unless there is a failure of all configured high priority links. At this time, LLT switches cluster communications to the first available low priority link. Traffic reverts to high priority links as soon as they are available.
Click the thumbnail above to view full-sized image.
LLT passes the status of the heartbeat to the Group Membership Services function of GAB. When LLT on a system no longer receives heartbeat messages from a peer on any configured LLT interface for a predefined time, LLT informs of the heartbeat loss for that system. GAB receives input on the status of heartbeat from all nodes and makes membership determination based on this information. When LLT informs GAB of a heartbeat loss, GAB marks the peer as DOWN and excludes the peer from the cluster. In most configurations, the I/O fencing module is utilized to ensure there was not a partition or split of the cluster interconnect. Once the new membership is determined, GAB informs processes on the remaining nodes that the cluster membership has changed. VCS then carries out failover actions to recover.
Understanding Split-brain and the Need for I/O Fencing
When VCS detects node failure, it attempts to take corrective action, which is determined by the cluster configuration. If the failing node hosted a service group, and one of the remaining nodes is designated in the group's SystemList, then VCS fails the service group over and imports shared storage to another node in the cluster. If the mechanism used to detect node failure breaks down, the symptoms appear identical to those of a failed node.
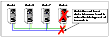
For example, in a four-node cluster, if a system fails, it stops sending heartbeat over the private interconnect. The remaining nodes then take corrective action. If the cluster interconnect fails, other nodes determine that their peer has departed and attempt to take corrective action. This may result in data corruption because both nodes attempt to take control of data storage in an uncoordinated manner.
Click the thumbnail above to view full-sized image.
This situation can also arise in other scenarios. If a system were so busy as to appear hung, it would be declared dead. This can also happen if the hardware supports a break and resume function. Dropping the system to prom (system controller) level with a break and a subsequent resume means the system could be declared as dead and the cluster reformed. The system could then return and start writing to the shared storage.
|