Release 2 (9.2)
Part Number A96519-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Backup and Recovery Concepts Release 2 (9.2) Part Number A96519-01 |
|
This chapter introduces the structures that are used during database recovery. The topics in this chapter include:
See Also:
|
This section contains these topics:
Crash recovery is used to recover from a failure either when a single-instance database crashes or all instances of an Oracle Real Application Clusters database crashes. Instance recovery refers to the case where a surviving instance recovers a failed instance in an Oracle Real Application Clusters database.
The goal of crash and instance recovery is to restore the data block changes located in the cache of the dead instance and to close the redo thread that was left open. Instance and crash recovery use only online redo log files and current online datafiles. Oracle recovers the redo threads of the dead instances together.
Crash and instance recovery have the following shared characteristics:
SHUTDOWN ABORT)Oracle performs this recovery automatically on two occasions:
The important point is that in both crash and instance recovery Oracle applies the redo automatically: no user intervention is required to supply redo logs. However, you can set parameters in the database server that can tune the duration of instance and crash recovery performance. Also, you can tune the rolling forward and rolling back phases of instance recovery separately. Finally, you can tune checkpointing so that recovery time is optimized.
| See Also:
Oracle9i Database Performance Tuning Guide and Reference for a discussion of instance recovery mechanics as well as instructions for tuning instance and crash recovery |
Media recovery is divided into the following types:
Typically, the term "media recovery" refers to recovery of datafiles. Block media recovery is a more specialized operation that you can only perform with RMAN.
Datafile media recovery is used to recover from a lost or damaged current datafile or control file. It is also used to recover changes that were lost when a tablespace went offline without the OFFLINE NORMAL option. Datafile media recovery and instance recovery have in common the requirement to repair database integrity. However, these types of recovery differ with respect to their additional features. Media recovery has the following characteristics:
The database cannot be opened if any of the online datafiles needs media recovery, nor can a datafile that needs media recovery be brought online until media recovery has been executed. The following scenarios necessitate media recovery:
OFFLINE NORMAL option.Unless the database is not open by any instance, datafile media recovery can only operate on offline datafiles. You can initiate datafile media recovery before opening a database even when crash recovery would have sufficed. If so, crash recovery still runs automatically at database open.
Note that when a file requires media recovery, you must perform media recovery even if all necessary changes are contained in the online logs. In other words, you must still run recovery even though the archived logs are not needed. Media recovery may find nothing to do -- and signal the "no recovery required" error -- if invoked for files that do not need recovery.
Block media recovery is a technique for restoring and recovering individual data blocks while all database files remain online and available. If corruption is limited to only a few blocks among a subset of database files, then block media recovery may be preferable to datafile recovery.
The interface to block media recovery is provided by RMAN. If you do not already use RMAN as your principal backup and recovery solution, then you can still perform block media recovery by cataloging into the RMAN repository the necessary user-managed datafile and archived redo log backups.
| See Also:
Oracle9i Recovery Manager User's Guide to learn how to catalog user-managed datafile and archived log backups and to perform block media recovery |
Media recovery proceeds through the application of redo data to the datafiles. Whenever a change is made to a datafile, the change is first recorded in the online redo logs. Media recovery selectively applies the changes recorded in the online and archived redo logs to the restored datafile to roll it forward.
This section contains these topics:
Database buffers in the buffer cache in the SGA are written to disk only when necessary, using a least-recently-used (LRU) algorithm. Because of the way that the database writer process uses this algorithm to write database buffers to datafiles, datafiles may contain some data blocks modified by uncommitted transactions and some data blocks missing changes from committed transactions.
Two potential problems can result if an instance failure occurs:
To solve this dilemma, two separate steps are generally used by Oracle for a successful recovery of a system failure: rolling forward with the redo log (cache recovery) and rolling back with the rollback or undo segments (transaction recovery).
The online redo log is a set of operating system files that record all changes made to any database buffer, including data, index, and rollback segments, whether the changes are committed or uncommitted. All changes to Oracle blocks are recorded in the online log.
The first step of recovery from an instance or disk failure is called cache recovery or rolling forward, and involves reapplying all of the changes recorded in the redo log to the datafiles. Because rollback data is also recorded in the redo log, rolling forward also regenerates the corresponding rollback segments
Rolling forward proceeds through as many redo log files as necessary to bring the database forward in time. Rolling forward usually includes online redo log files (instance recovery or media recovery) and may include archived redo log files (media recovery only).
After rolling forward, the data blocks contain all committed changes. They may also contain uncommitted changes that were either saved to the datafiles before the failure, or were recorded in the redo log and introduced during cache recovery.
You can run Oracle in either manual undo management mode or automatic undo management mode. In manual mode, you must create and manage rollback segments to record the before-image of changes to the database. In automatic undo management mode, you create one or more undo tablespaces. These undo tablespaces contain undo segments similar to traditional rollback segments. The main difference is that Oracle manages the undo for you.
Undo blocks (whether in rollback segments or automatic undo tablespaces) record database actions that should be undone during certain database operations. In database recovery, the undo blocks roll back the effects of uncommitted transactions previously applied by the rolling forward phase.
After the roll forward, any changes that were not committed must be undone. Oracle applies undo blocks to roll back uncommitted changes in data blocks that were either written before the crash or introduced by redo application during cache recovery. This process is called rolling back or transaction recovery.
Figure 3-1 illustrates rolling forward and rolling back, the two steps necessary to recover from any type of system failure.
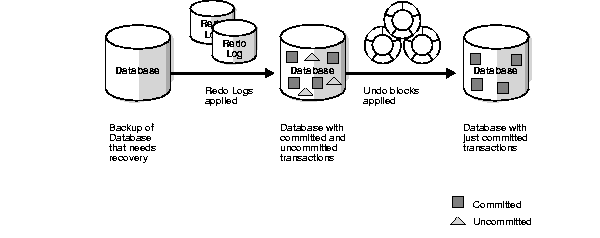
Oracle can roll back multiple transactions simultaneously as needed. All transactions systemwide that were active at the time of failure are marked as dead. Instead of waiting for SMON to roll back dead transactions, new transactions can recover blocking transactions themselves to get the row locks they need.
Media recovery updates a backup to either to the current or to a specified noncurrent time. When performing media recovery, you can recover the whole database, a tablespace, or a datafile. In any case, you always use a restored backup to perform the recovery.
This section contains the follow topics:
Complete recovery involves using redo data or incremental backups combined with a backup of a database, tablespace, or datafile to update it to the most current point in time. It is called complete because Oracle applies all of the redo changes contained in the archived and online logs to the backup. Typically, you perform complete media recovery after a media failure damages datafiles or the control file.
You can perform complete recovery on a database, tablespace, or datafile. If you are performing complete recovery on the whole database, then whether you are using RMAN or SQL*Plus you must:
If you are performing complete recovery on a tablespace or datafile, then you must:
Incomplete recovery uses a backup to produce a noncurrent version of the database. In other words, you do not apply all of the redo records generated after the most recent backup. You usually perform incomplete recovery of the whole database in the following situations:
To perform incomplete media recovery, you must restore all datafiles from backups created prior to the time to which you want to recover and then open the database with the RESETLOGS option when recovery completes. The RESETLOGS operation creates a new incarnation of the database--in other words, a database with a new stream of log sequence numbers starting with log sequence 1.
The tablespace point-in-time recovery (TSPITR) feature enables you to recover one or more tablespaces to a point-in-time that is different from the rest of the database. TSPITR is most useful when you want to:
| See Also:
Oracle9i User-Managed Backup and Recovery Guide to learn how to perform user-managed TSPITR, and Oracle9i Recovery Manager User's Guide to learn how to perform TSPITR with RMAN. |
Because you are not completely recovering the database to the most current time, you must tell Oracle when to terminate recovery. You can perform the following types of media recovery.
You have a choice between two basic methods for recovering physical files. You can:
RECOVER commandWhichever method you choose, you can recover a database, tablespace, or datafile. Before performing media recovery, you need to determine which datafiles to recover. Often you can use the fixed view V$RECOVER_FILE. This view lists all files that require recovery and explains the error that necessitates recovery.
| See Also:
Oracle9i Recovery Manager User's Guide for more about using |
The basic RMAN recovery commands are RESTORE and RECOVER. Use RESTORE to restore datafiles from backup sets or from image copies on disk, either to their current location or to a new location. You can also restore backup sets containing archived redo logs. Use the RMAN RECOVER command to perform media recovery and apply archived logs or incremental backups.
RMAN automates the procedure for recovering and restoring your backups and copies. For example, run the following commands from within RMAN to restore and recover the database to its current time:
SHUTDOWN IMMEDIATE; # shuts down database STARTUP MOUNT; # starts and mounts database RESTORE DATABASE; # restores all datafiles RECOVER DATABASE; # recovers database using all available redo ALTER DATABASE OPEN; # reopens the database
| See Also:
Oracle9i Recovery Manager User's Guide to learn how to restore and recovery using RMAN |
If you do not use RMAN, then you can restore backups with operating system utilities and then run the SQL*Plus RECOVER command to recover the database. You should follow these basic steps:
If you cannot restore a datafile to its original location, then relocate the restored datafile and change the location in the control file.
RECOVER command to recover the datafile backups.For example, assume that you lose the /oracle/dbs/users1.dbf datafile, which is contained in the users tablespace, to a media failure. Also, assume that you have a backup called /dsk2/backup/users1.dbf on a separate disk drive. You discover that the datafile is missing because a query returns an error saying that the file is missing.
Your first step is to take the users tablespace offline. For example, you run this SQL statement:
SQL> ALTER TABLESPACE users OFFLINE IMMEDIATE;
Then, you restore the backup of users1.dbf using an operating system utility. For example, you run this UNIX command:
% cp /dsk2/backup/users1.dbf /oracle/dbs/users1.dbf
Assuming that you have all necessary archived redo logs, you can recover the datafile with the following SQL*Plus command:
SQL> RECOVER AUTOMATIC DATAFILE '/oracle/dbs/users1.dbf';
Finally, bring the tablespace online as follows:
SQL> ALTER TABLESPACE users ONLINE;
| See Also:
Oracle9i User-Managed Backup and Recovery Guide to learn how to restore and recover by means of operating system utilities and SQL*Plus |
|
 Copyright © 2001, 2002 Oracle Corporation. All Rights Reserved. |
|

