Release 2 (9.2)
Part Number A96572-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i User-Managed Backup and Recovery Guide Release 2 (9.2) Part Number A96572-01 |
|
This chapter describes how to recover a database, and includes the following topics:
During complete or incomplete media recovery, Oracle applies redo log files to the datafiles during the roll forward phase of media recovery. Because changes to undo segments are recorded in the online redo log, rolling forward regenerates the corresponding undo segments. Rolling forward proceeds through as many redo log files as necessary to bring the database forward in time.
If you do not use Recovery Manager (RMAN) to perform recovery, then you should use the SQL*Plus RECOVER command. It is also possible to use the SQL statement ALTER DATABASE RECOVER, but it is highly recommended that you use the SQL*Plus RECOVER command instead.
This section contains these topics:
To start any type of media recovery, you must adhere to the following restrictions:
Oracle Corporation recommends that you use the SQL*Plus RECOVER command rather than the ALTER DATABASE RECOVER statement to perform media recovery. In almost all cases, the SQL*Plus method is easier.
When using SQL*Plus to perform media recovery, the easiest strategy is to perform automatic recovery. Automatic recovery initiates recovery without manually prompting SQL*Plus to apply each individual archived log.
When using SQL*Plus, you have two options for automating the application of the default filenames of archived redo logs needed during recovery:
SET AUTORECOVERY ON before issuing the RECOVER commandAUTOMATIC keyword as an option of the RECOVER commandIn either case, no interaction is required when you issue the RECOVER command if the necessary files are in the correct locations with the correct names.
The filenames used when you use automatic recovery are derived from the concatenated values of LOG_ARCHIVE_FORMAT with LOG_ARCHIVE_DEST_n, where n is the highest value among all enabled, local destinations.
For example, assume the following initialization parameter settings are in effect in the database instance:
LOG_ARCHIVE_DEST_1 = "LOCATION=/arc_dest/loc1/" LOG_ARCHIVE_DEST_2 = "LOCATION=/arc_dest/loc2/" LOG_ARCHIVE_DEST_STATE_1 = DEFER LOG_ARCHIVE_DEST_STATE_2 = ENABLE LOG_ARCHIVE_FORMAT = arch_%t_%s.arc
In this case, SQL*Plus automatically suggests the filename /arc_dest/loc2/arch_%t_%s.arc (where %t is the thread and %s is the sequence).
If you run SET AUTORECOVERY OFF, which is the default option, then you must enter the filenames manually, or accept the suggested default filename by pressing the Enter key.
Run the SET AUTORECOVERY ON command to enable on automatic recovery.
To automate the recovery using SET AUTORECOVERY:
% cp /fs2/BACKUP/tbs* /oracle/dbs
STARTUP MOUNT
SET AUTORECOVERY ON
RECOVER DATABASE
Oracle automatically suggests and applies the necessary archived logs, as in this sample output:
ORA-00279: change 53577 generated at 01/26/00 19:20:58 needed for thread 1 ORA-00289: suggestion : /oracle/work/arc_dest/arcr_1_802.arc ORA-00280: change 53577 for thread 1 is in sequence #802 Log applied. ORA-00279: change 53584 generated at 01/26/00 19:24:05 needed for thread 1 ORA-00289: suggestion : /oracle/work/arc_dest/arcr_1_803.arc ORA-00280: change 53584 for thread 1 is in sequence #803 ORA-00278: log file "/oracle/work/arc_dest/arcr_1_802.arc" no longer needed for this recovery Log applied. Media recovery complete.
ALTER DATABASE OPEN;
Besides using SET AUTORECOVERY to turn on automatic recovery, you can also simply specify the AUTOMATIC keyword in the RECOVER command.
To automate the recovery with the RECOVER AUTOMATIC command:
% cp /oracle/work/BACKUP/tbs* /oracle/dbs
STARTUP MOUNT
AUTOMATIC keyword. This example performs automatic recovery on the whole database:
RECOVER AUTOMATIC DATABASE
ORA-00279: change 53577 generated at 01/26/00 19:20:58 needed for thread 1 ORA-00289: suggestion : /oracle/work/arc_dest/arcr_1_802.arc ORA-00280: change 53577 for thread 1 is in sequence #802 Log applied. ORA-00279: change 53584 generated at 01/26/00 19:24:05 needed for thread 1 ORA-00289: suggestion : /oracle/work/arc_dest/arcr_1_803.arc ORA-00280: change 53584 for thread 1 is in sequence #803 ORA-00278: log file "/oracle/work/arc_dest/arcr_1_802.arc" no longer needed for this recovery Log applied. Media recovery complete.
ALTER DATABASE OPEN;
If you use an Oracle Real Application Clusters configuration, and if you are performing incomplete recovery or using a backup control file, then Oracle can only compute the name of the first archived redo log file from the first redo thread. You may have to manually apply the first log file from the other redo threads. After the first log file in a given thread has been supplied, Oracle can suggest the names of the subsequent logs in this thread.
Recovering when the archived logs are in their default location is the simplest case. As a log is needed, Oracle suggests the filename. If you are running nonautomatic media recovery with SQL*Plus, then the output is displayed in this format:
ORA-00279: Change #### generated at DD/MM/YY HH:MM:SS needed for thread# ORA-00289: Suggestion : logfile ORA-00280: Change #### for thread # is in sequence # Specify log: [<RET> for suggested | AUTO | FROM logsource | CANCEL ]
For example, SQL*Plus displays output similar to the following:
ORA-00279: change 53577 generated at 01/26/00 19:20:58 needed for thread 1 ORA-00289: suggestion : /oracle/arc_dest/arcr_1_802.arc ORA-00280: change 53577 for thread 1 is in sequence #802 Specify log: [<RET> for suggested | AUTO | FROM logsource | CANCEL ]
Similar messages are returned when you use an ALTER DATABASE ... RECOVER statement. However, no prompt is displayed.
Oracle suggests archived redo log filenames by concatenating the current values of the initialization parameters LOG_ARCHIVE_DEST_n (where n is the highest value among all enabled, local destinations) and LOG_ARCHIVE_FORMAT and using log history information from the control file. For example, the following are possible settings for archived redo logs:
LOG_ARCHIVE_DEST_1 = 'LOCATION = /oracle/arc_dest/' LOG_ARCHIVE_FORMAT = arcr_%t_%s.arc SELECT NAME FROM V$ARCHIVED_LOG; NAME ------------------------------- /oracle/arc_dest/arcr_1_467.arc /oracle/arc_dest/arcr_1_468.arc /oracle/arc_dest/arcr_1_469.arc
Thus, if all the required archived log files are mounted at the LOG_ARCHIVE_DEST_1 destination, and if the value for LOG_ARCHIVE_FORMAT is never altered, then Oracle can suggest and apply log files to complete media recovery automatically.
Performing media recovery when archived logs are not in their default location adds an extra step into the recovery procedure. You have the following mutually exclusive options:
LOG_ARCHIVE_DEST_n parameter that specifies the location of the archived redo logs, then recover as usual.SET statement in SQL*Plus to specify the nondefault log location before recovery, or the LOGFILE parameter of the RECOVER commandYou can edit the initialization parameter file or issue ALTER SYSTEM statements to change the default location of the archived redo logs.
To change the default archived log location before recovery:
% cp /disk3/arc_bak/* /disk2/tmp
ALTER SYSTEM statements while the instance is started, or edit the initialization parameter file and then start the database instance. For example, while the instance is shut down edit the parameter file as follows:
LOG_ARCHIVE_DEST_1 = 'LOCATION=/disk2/tmp/arc' LOG_ARCHIVE_FORMAT = r_%t_%s.arc
STARTUP MOUNT
RECOVER DATABASE
In some cases, you may want to override the current setting for the archiving destination parameter as a source for redo log files. For example, assume that a database is open and an offline tablespace must be recovered, but not enough space is available to mount the necessary redo log files at the location specified by the archiving destination parameter. In this case, use one of the following procedures.
To recover using logs in a nondefault location with SET LOGSOURCE:
% cp /disk1/oracle/arc_dest/* /disk2/temp
LOGSOURCE parameter of the SET statement or the RECOVER ... FROM clause of the ALTER DATABASE statement. For example, start SQL*Plus and run:
SET LOGSOURCE "/disk2/temp"
RECOVER AUTOMATIC TABLESPACE offline_tbsp
SET LOGSOURCE and simply run:
RECOVER AUTOMATIC TABLESPACE offline_tbsp FROM "/disk2/temp"
If you are using SQL*Plus's recovery options (not SQL statements), then each time Oracle successfully applies a redo log file, the following message is returned:
Log applied.
Oracle then prompts for the next log in the sequence or, if the most recently applied log is the last required log, terminates recovery.
If the suggested file is incorrect or you provide an incorrect filename, then Oracle returns an error message. For example, you may see something like:
ORA-00308: cannot open archived log "/oracle/work/arc_dest/arcr_1_811.arc" ORA-27037: unable to obtain file status SVR4 Error: 2: No such file or directory Additional information: 3
Recovery cannot continue until the required redo log file is applied. If Oracle returns an error message after supplying a redo log filename, then the following responses are possible.
When you perform complete recovery, you recover the backups to the current SCN. You can either recover the whole database at once or recover individual tablespaces or datafiles. Because you do not have to open the database with the RESETLOGS option after complete recovery as you do after incomplete recovery, you have the option of recovering some datafiles at one time and the remaining datafiles later.
This section describes the steps necessary to complete media recovery operations, and includes the following topics:
| See Also:
Oracle9i Backup and Recovery Concepts to familiarize yourself with fundamental recovery concepts and strategies |
This section describes steps to perform complete recovery while the database is not open. You can recover either all damaged datafiles in one operation, or perform individual recovery of each damaged datafile in separate operations.
Perform the media recovery in the following stages:
In this stage, you shut down the instance and inspect the media device that is causing the problem.
To prepare for closed database recovery:
ABORT option:
SHUTDOWN ABORT
In this stage, you restore all necessary backups.
To restore the necessary files:
For example, if /oracle/dbs/tbs_10.f is the only damaged file, then you may consult your records and determine that /oracle/backup/tbs_10.backup is the most recent backup of this file. If you do not have a backup of a specific datafile, then you may be able to create an empty replacement file that can be recovered.
/oracle/dbs/tbs_10.f to its default location might enter:
% cp /oracle/backup/tbs_10.backup /oracle/dbs/tbs_10.f
Follow these guidelines when determining where to restore datafile backups:
| If . . . | Then . . . |
|---|---|
|
The hardware problem is repaired and you can restore the datafiles to their default locations |
Restore the datafiles to their default locations and begin media recovery. |
|
The hardware problem persists and you cannot restore datafiles to their original locations |
Restore the datafiles to an alternative storage device. Indicate the new location of these files in the control file. Use the operation described in "Renaming and Relocating Datafiles" in the Oracle9i Database Administrator's Guide, as necessary. |
In the final stage, you recover the datafiles that you have restored.
To recover the restored datafiles:
STARTUP MOUNT
V$DATAFILE view. For example, enter:
SELECT NAME,STATUS FROM V$DATAFILE;
/oracle/dbs/tbs_10.f is online, enter the following:
ALTER DATABASE DATAFILE '/oracle/dbs/tbs_10.f' ONLINE;
If a specified datafile is already online, then Oracle ignores the statement. If you prefer, create a script to bring all datafiles online at once as in the following:
SPOOL onlineall.sql SELECT 'ALTER DATABASE DATAFILE '''||name||''' ONLINE;' FROM V$DATAFILE; SPOOL OFF SQL> @onlineall
RECOVER command:
RECOVER DATABASE # recovers whole database RECOVER TABLESPACE users # recovers specific tablespace RECOVER DATAFILE '/oracle/dbs/tbs_10'; # recovers specific datafile
Follow these guidelines when deciding which statement to execute:
Media recovery complete.
If no archived redo log files are required for complete media recovery, then Oracle applies all necessary online redo log files and terminates recovery.
ALTER DATABASE OPEN;
| See Also:
"Performing User-Managed Media Recovery: Overview" for more information about applying redo log files |
It is possible for a media failure to occur while the database remains open, leaving the undamaged datafiles online and available for use. Oracle automatically takes the damaged datafiles offline--but not the tablespaces that contain them--if the database writer is unable to write to them. Queries that cannot read damaged files return errors, but Oracle does not take the files offline because of the failed queries. For example, you may run a query and see output such as:
ERROR at line 1: ORA-01116: error in opening database file 11 ORA-01110: data file 11: '/oracle/dbs/tbs_32.f' ORA-27041: unable to open file SVR4 Error: 2: No such file or directory Additional information: 3
The media recovery procedure in this section cannot be used to perform complete media recovery on the datafiles of the SYSTEM tablespace. If the media failure damages any datafiles of the SYSTEM tablespace, then Oracle automatically shuts down the database.
Perform media recovery in these stages:
See Also:
|
In this stage, you take affected tablespaces offline and inspect the media device that is causing the problem.
To prepare for datafile recovery when the database is open:
users contains damaged datafiles, enter:
ALTER TABLESPACE users OFFLINE TEMPORARY;
In this stage, you restore all necessary backups in the offline tablespaces.
To restore datafiles in an open database:
users you might enter:
ALTER DATABASE RENAME FILE '/d1/oracle/dbs/tbs1.f' TO '/d3/oracle/dbs/tbs1.f';
| See Also:
Oracle9i SQL Reference for more information about |
In the final stage, you recover the datafiles in the offline tablespaces.
To recover offline tablespaces in an open database:
SYSTEM to database prod1:
% sqlplus SYSTEM/manager@prod1
users and sales tablespaces as follows:
RECOVER TABLESPACE users, sales # begins recovery on datafiles in users and sales
|
Note: For maximum performance, use parallel recovery to recover the datafiles. See "Performing Media Recovery in Parallel". |
RECOVER AUTOMATIC or SET AUTORECOVERY ON, Oracle prompts for each required redo log file.
Oracle continues until all required archived redo log files have been applied to the restored datafiles. The online redo log files are then automatically applied to the restored datafiles to complete media recovery.
If no archived redo log files are required for complete media recovery, then Oracle does not prompt for any. Instead, all necessary online redo log files are applied, and media recovery is complete.
users and sales online, issue the following statements:
ALTER TABLESPACE users ONLINE; ALTER TABLESPACE sales ONLINE;
| See Also:
Oracle9i Database Administrator's Guide for more information about creating datafiles |
This section describes the steps necessary to complete the different types of incomplete media recovery operations, and includes the following topics:
Note that if your database is affected by seasonal time changes (for example, daylight savings time), then you may experience a problem if a time appears twice in the redo log and you want to recover to the second, or later time. To handle time changes, perform cancel-based or change-based recovery.
In this phase, you examine the source of the media problem.
To prepare for cancel-based recovery:
SHUTDOWN ABORT
In this phase, you restore a whole database backup.
To restore the files necessary for cancel-based recovery and bring them online:
| If . . . | Then . . . |
|---|---|
|
You do not have a backup of a datafile |
Create an empty replacement file that can be recovered as described in "Re-Creating Datafiles When Backups Are Unavailable". |
|
A datafile was added after the intended time of recovery |
Do not restore a backup of this file because it will no longer be used for the database after recovery completes. |
|
The hardware problem causing the failure has been solved and all datafiles can be restored to their default locations |
Restore the files as described in "Restoring Datafiles" and skip Step 5 of this procedure. |
|
A hardware problem persists |
Restore damaged datafiles to an alternative storage device. |
% sqlplus SYS/change_on_install@prod1
STARTUP MOUNT
ALTER DATABASE RENAME FILE '/oracle/dbs/df2.f' TO '/oracle/newloc/df2.f';
V$DATAFILE view. For example, enter:
SELECT NAME,STATUS FROM V$DATAFILE;
/oracle/dbs/tbs_10.f is online, enter the following:
ALTER DATABASE DATAFILE '/oracle/dbs/tbs_10.f' ONLINE;
If a specified datafile is already online, Oracle ignores the statement. If you prefer, create a script to bring all datafiles online at once as in the following:
SPOOL onlineall.sql SELECT 'ALTER DATABASE DATAFILE '''||name||''' ONLINE;' FROM V$DATAFILE; SPOOL OFF SQL> @onlineall
In cancel-based recovery, recovery proceeds by prompting you with the suggested filenames of archived redo log files. Recovery stops when you specify CANCEL instead of a filename or when all redo has been applied to the datafiles.
Cancel-based recovery is better than change-based or time-based recovery if you want to control which archived log terminates recovery. For example, you may know that you have lost all logs past sequence 1234, so you want to cancel recovery after log 1233 is applied.
You should perform cancel-based media recovery in these stages:
To perform cancel-based recovery:
% sqlplus '/ AS SYSDBA'
STARTUP MOUNT
RECOVER DATABASE UNTIL CANCEL
If you are using a backup control file with this incomplete recovery, then specify the USING BACKUP CONTROLFILE option in the RECOVER command.
RECOVER DATABASE UNTIL CANCEL USING BACKUP CONTROLFILE
LOG_ARCHIVE_DEST_1 and requests you to stop or proceed with applying the log file. Note that if the control file is a backup, then you must supply the names of the online logs if you want to apply the changes in these logs.
CANCEL
Oracle returns a message indicating whether recovery is successful. Note that if you cancel recovery before all the datafiles have been recovered to a consistent SCN and then try to open the database, you will get an ORA-1113 error if more recovery is necessary for the file. You can query V$RECOVER_FILE to determine whether more recovery is needed, or if a backup of a datafile was not restored prior to starting incomplete recovery.
RESETLOGS mode. You must always reset the online logs after incomplete recovery or recovery with a backup control file. For example, enter:
ALTER DATABASE OPEN RESETLOGS;
This section describes how to perform the time-based media recovery procedure in the following stages:
To perform time-based recovery:
RECOVER DATABASE UNTIL TIME statement to begin time-based recovery. The time is always specified using the following format, delimited by single quotation marks: 'YYYY-MM-DD:HH24:MI:SS'. The following statement recovers the database up to a specified time:
RECOVER DATABASE UNTIL TIME '2000-12-31:12:47:30'
If a backup of the control file is being used with this incomplete recovery (that is, a control file backup or re-created control file was restored), then indicate this in the statement used to start recovery. The following statement recovers the database up to a specified time using a control file backup:
RECOVER DATABASE UNTIL TIME '2000-12-31:12:47:30' USING BACKUP CONTROLFILE
LOG_ARCHIVE_DEST_1 and requests you to stop or proceed with applying the log file. If the control file is a backup, then you after the archived logs have been applied you must supply the names of the online logs in order to apply their changes.RESETLOGS mode. You must always reset the online logs after incomplete recovery or recovery with a backup control file. For example, enter:
ALTER DATABASE OPEN RESETLOGS;
This section describes how to perform recovery to a specified SCN in these stages:
To perform change-based recovery:
RECOVER DATABASE UNTIL CHANGE 10034;
LOG_ARCHIVE_DEST_1 and requests you to stop or proceed with applying the log file. If the control file is a backup, then you after the archived logs have been applied you must supply the names of the online logs in order to apply their changes.RESETLOGS mode. You must always reset the online logs after incomplete recovery or recovery with a backup control file. For example, enter:
ALTER DATABASE OPEN RESETLOGS;
If a database is in NOARCHIVELOG mode and a media failure damages some or all of the datafiles, then the only option for recovery is usually to restore the most recent whole database backup. If you are using Export to supplement regular backups, then you can also attempt to restore the database by importing an exported backup of the database into a re-created database or a database restored from an old backup.
The disadvantage of NOARCHIVELOG mode is that to recover the database from the time of the most recent full backup up to the time of the media failure, you have to reenter manually all of the changes executed in that interval. If the database was in ARCHIVELOG mode, however, the redo log covering this interval would have been available as archived log files or online log files. Using archived redo logs would have enabled you to use complete or incomplete recovery to reconstruct your database, thereby minimizing the amount of lost work.
If you have a database damaged by media failure and operating in NOARCHIVELOG mode, and if you want to restore from your most recent consistent whole database backup (your only option at this point), then follow the procedures in this section.
In this scenario, the media failure is repaired so that you are able to restore all database files to their original location.
To restore the most recent whole database backup to the default location:
SHUTDOWN IMMEDIATE
% cp /oracle/work/BACKUP/tbs* /oracle/dbs # restores datafiles % cp /oracle/work/BACKUP/cf.f /oracle/dbs # restores control file
RECOVER DATABASE UNTIL CANCEL CANCEL
RESETLOGS mode. This command resets the current redo log sequence to 1:
ALTER DATABASE OPEN RESETLOGS;
A RESETLOGS operation invalidates all redo in the online logs. Restoring from a whole database backup and then resetting the log discards all changes to the database made from the time the backup was taken to the time of the failure.
In this scenario, you restore the database files to an alternative location because the original location is damaged by a media failure.
To restore the most recent whole database backup to a new location:
SHUTDOWN IMMEDIATE
% cp /disk2/BACKUP/tbs* /disk3/oracle/dbs # default location % cp /disk2/BACKUP/cf.f /disk3/oracle/dbs # new location % cp /disk2/BACKUP/system01.dbf /disk4/temp # new location
CONTROL_FILES = "/disk3/oracle/dbs/cf.f"
STARTUP MOUNT
ALTER DATABASE RENAME FILE '/disk1/oracle/dbs/system01.dbf' TO '/disk4/temp/system01.dbf';
ALTER DATABASE RENAME FILE '/disk1/oracle/dbs/log1.f' TO '/disk3/oracle/dbs/log1.f'; ALTER DATABASE RENAME FILE '/disk1/oracle/dbs/log2.f' TO '/disk3/oracle/dbs/log2.f';
RECOVER DATABASE UNTIL CANCEL; CANCEL;
RESETLOGS mode. This command resets the current redo log sequence to 1:
ALTER DATABASE OPEN RESETLOGS;
A RESETLOGS operation invalidates all redo in the online logs. Restoring from a whole database backup and then resetting the log discards all changes to the database made from the time the backup was taken to the time of the failure.
| See Also:
Oracle9i Database Administrator's Guide for more information about renaming and relocating datafiles, and Oracle9i SQL Reference for more information about |
Use parallel media recovery to tune the roll forward phase of media recovery. In parallel media recovery, Oracle uses a "division of labor" approach to allocate different processes to different data blocks while rolling forward, thereby making the procedure more efficient. For example, if parallel recovery is performed with PARALLEL 4, and only one datafile is recovered, then four spawned processes read blocks from the datafile and apply records instead of only one process.
The SQL*Plus RECOVER PARALLEL command specifies parallel media recovery (the default is NOPARALLEL). This command selects a degree of parallelism equal to the number of CPUs available on all participating instances times the value of the PARALLEL_THREADS_PER_CPU initialization parameter.
The format for the RECOVER PARALLEL command is the following:
RECOVER PARALLEL integer;
The integer variable sets the number of recovery processes used for media recovery. If you use a Real Application Clusters configuration, then Oracle decides how to distribute these recovery processes among the instances. If integer is not specified, then Oracle picks a default number of recovery processes.
| Note:
The |
See Also:
|
Whenever you perform incomplete recovery or recovery with a backup control file, you must reset the online logs when you open the database. The new version of the reset database is called a new incarnation. All archived logs generated after the point of the RESETLOGS on the old incarnation are invalid in the new incarnation.
If you perform complete recovery, then you do not have to open the database with the RESETLOGS option. All previous backups and archived logs created during the lifetime of this incarnation of the database are valid.
This section contains the following topics:
Whenever you open the database with the RESETLOGS option, all datafiles get a new RESETLOGS SCN and time stamp, and the log sequence number is reset to 1. Archived redo logs also have these two values in their file header. Because Oracle will not apply an archived redo log to a datafile unless the RESETLOGS SCN and time stamps match, the RESETLOGS operations prevents you from corrupting your datafiles with old archived logs.
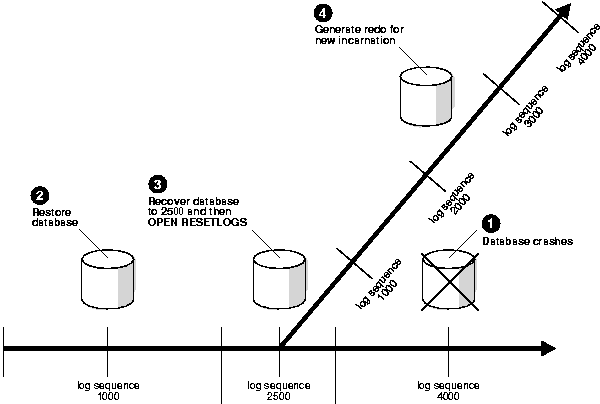
Figure 4-1 shows the case of a database that can only be recovered to log sequence 2500 because an archived redo log is missing. At log sequence 4000, the database crashes. You restore the log sequence 1000 backup and prepare for complete recovery. Unfortunately, one of your archived redo logs is corrupted. The log before the missing log contains log sequence 2500, so you recover to this point and open with the RESETLOGS option. The log sequence is now reset to 1.
As the diagram illustrates, you generate new changes in the new incarnation of the database, eventually reaching log sequence 4000. The changes between log sequence 2500 and log sequence 4000 for the new incarnation of the database are completely different from the changes between log sequence 2500 and log sequence 4000 for the old incarnation. Oracle does not allow you to apply logs from an old incarnation to the new incarnation. You cannot restore backups from before log sequence 2500 in the old incarnation to the new incarnation.
To open the database with the RESETLOGS option, all datafiles must be recovered to the same SCN. If a backup control file is restored, then the backup control file must also be recovered to the same SCN.
The RESETLOGS option is always required after incomplete media recovery or recovery using a backup control file. Resetting the redo log does the following:
Use the following rules when deciding whether to specify RESETLOGS or NORESETLOGS:
RESETLOGS option after incomplete recovery. For example, you must have specified a previous time or SCN, not one in the future.RESETLOGS if you used a backup of the control file in recovery, regardless of whether you performed complete or incomplete recovery.NORESETLOGS option after performing complete media recovery (unless you used a backup control file, in which case you must open with the RESETLOGS option).RESETLOGS option if you are using the archived logs of the database for a standby database. If you must reset the online logs, then you have to re-create the standby database.To preserve the log sequence number when opening a database after media recovery, execute either of the following statements:
ALTER DATABASE OPEN NORESETLOGS; ALTER DATABASE OPEN;
To reset the log sequence number when opening a database after recovery and thereby create a new incarnation of the database, execute the following statement:
ALTER DATABASE OPEN RESETLOGS;
If you open with the RESETLOGS option, Oracle returns different messages depending on whether recovery was complete or incomplete. If the recovery was complete, then the following message appears in the alert_SID.log file:
RESETLOGS after complete recovery through change scn
If the recovery was incomplete, then this message is reported in the alert_SID.log file, where scn refers to the end point of incomplete recovery:
RESETLOGS after incomplete recovery UNTIL CHANGE scn
If you attempt to OPEN RESETLOGS when you should not, or if you neglect to reset the log when you should, then Oracle returns an error and does not open the database. Correct the problem and try again.
| See Also:
"About User-Managed Media Recovery Problems" for descriptions of situations that can cause |
This section describes actions that you should perform after opening the database in RESETLOGS mode.
Immediately shut down the database normally and make a full database backup. Otherwise, you will not be able to recover changes made after you reset the logs. Until you take a full backup, the only way to recover is to repeat the procedures you just finished, up to resetting the logs. You do not need to make another backup of the database if you did not reset the log sequence.
In general, backups made before a RESETLOGS operation are not allowed in the new incarnation. There is, however, an exception to the rule: you can restore a pre-RESETLOGS backup only if Oracle does not need to access archived redo logs from before the RESETLOGS to perform recovery.
After opening the database using the RESETLOGS option, check the alert_SID.log to see whether Oracle detected inconsistencies between the data dictionary and the control file, for example, a datafile that the data dictionary includes but does not list in the new control file.
If a datafile exists in the data dictionary but not in the new control file, then Oracle creates a placeholder entry in the control file under MISSINGnnnn (where nnnn is the file number in decimal). MISSINGnnnn is flagged in the control file as being offline and requiring media recovery.
The datafile corresponding to MISSINGnnnn can be made accessible by renaming MISSINGnnnn so that it points to the datafile only if the datafile was read-only or offline normal between the time the backup was taken to the point where the RESETLOGS is issued.On the other hand, if MISSINGnnnn corresponds to a datafile that was not read-only or offline normal during the recovery period, then the rename operation cannot be used to make the datafile accessible, because the datafile requires media recovery that is precluded by the results of RESETLOGS. In this case, you must drop the tablespace containing the datafile.
In contrast, if a datafile indicated in the control file is not in the data dictionary, Oracle removes references to it from the new control file. In both cases, Oracle includes an message in the alert_SID.log file to let you know what was found.
In releases prior to Oracle8, DBAs typically backed up online logs when performing cold consistent backups to avoid opening the database with the RESETLOGS option (if they were planning to restore immediately).
A classic example of this technique was disk maintenance, which required the database to be backed up, deleted, the disks reconfigured, and the database restored. DBAs realized that by not restarting in RESETLOGS mode, they would not have to back up the database immediately after the restore. This backup was required since it was impossible to perform recovery on a backup taken before the RESETLOGS--especially if any errors occurred after resetting the logs.
You can restore the following backups made before a RESETLOGS in a new incarnation:
RESETLOGS)RESETLOGS)RESETLOGS, that is, you do not perform further recovery or alter the datafiles between the backup and the RESETLOGS--but only if you have a control file that is valid after you open RESETLOGSYou are prevented from restoring backups of read/write tablespaces that were not made immediately before the RESETLOGS. This restriction applies even if no changes were made to the datafiles in the read/write tablespace between the backup and the ALTER DATABASE OPEN RESETLOGS. Because the checkpoint in the datafile header of a backup will be older than the checkpoint in the control file, Oracle has to search the archived logs to determine whether changes need to be applied--and the archived logs generated prior to the RESETLOGS are not valid in the new incarnation.
The following scenario illustrates a situation when you can use a backup created before a RESETLOGS. Suppose you wish to perform hardware striping reconfiguration, which requires the database files to be backed up and deleted, the hardware reconfigured, and the database restored.
On Friday night you perform the following actions:
SHUTDOWN IMMEDIATE
% cp /oracle/dbs/* /oracle/backup
% cp /oracle/backup/* /oracle/dbs
STARTUP MOUNT
RECOVER DATABASE UNTIL CANCEL
RESETLOGS option. For example, enter:
ALTER DATABASE OPEN RESETLOGS;
On Saturday morning the scheduled jobs run, generating archived logs. If a hardware error occurs Saturday night that requires you to restore the whole database, then you can restore the backup taken immediately before opening with the RESETLOGS option, and roll forward using the logs produced on Saturday.
On Saturday night you do the following:
SHUTDOWN ABORT
% cp /oracle/backup/* /oracle/dbs
SET AUTORECOVERY ON to automate the log application. For example, enter:
SET AUTORECOVERY ON RECOVER DATABASE
STARTUP
In this scenario, if you had opened the database after the Friday night backup and before opening the database with RESETLOGS, or, if you did not have a control file from after opening the database, then you would not be able to use the Friday night backup to roll forward. You must have a backup after opening the database with the RESETLOGS option in order to be able to recover.
If you start media recovery and must then interrupt it, for example, because a recovery operation must end for the night and resume the next morning, then take either of the following actions:
CANCEL when prompted for a redo log file.After recovery is canceled, you can resume it later with the RECOVER command. Recovery resumes where it left off when it was canceled.
Several factors may cause you to restart recovery. For example, if you want to restart with a different backup or want to use the same backup but need to change the end time to an earlier point in time than you initially specified, then the entire operation must recommence by restoring a backup.
If you are recovering parts of database with RECOVER TABLESPACE or RECOVER DATAFILE, then you will have to restart recovery and finish recovery in order to make these parts of the database available.
If you are performing incomplete recovery of the whole database, then you may be able to open the database read only or RESETLOGS after canceling media recovery. This strategy can succeed if all datafiles have been recovered to a consistent SCN, and also works even after interrupting media recovery. If not all datafiles have been recovered to a consistent SCN, then the RESETLOGS may fail, requiring you to perform more media recovery.
Before performing media recovery, make sure that you understand the following issues:
You can create tables and indexes with the CREATE TABLE AS SELECT statement. You can also specify that Oracle create them as unrecoverable. When you create a table or index as unrecoverable, Oracle does not generate redo log records for the operation. Thus, you cannot recover objects created unrecoverable, even if you are running in ARCHIVELOG mode.
|
Note: If you cannot afford to lose tables or indexes created unrecoverable, then make a backup after the unrecoverable table or index is created. |
Be aware that when you perform media recovery, and some tables or indexes are created as recoverable while others are unrecoverable, the unrecoverable objects are marked logically corrupt by the RECOVER operation. Any attempt to access the unrecoverable objects returns an ORA-01578 error message. Drop the unrecoverable objects and re-create them if needed.
Because it is possible to create a table unrecoverable and then create a recoverable index on that table, the index is not marked as logically corrupt after you perform media recovery. The table was unrecoverable (and thus marked as corrupt after recovery), however, so the index points to corrupt blocks. The index must be dropped, and the table and index must be re-created if necessary.
| See Also:
Oracle9i Data Guard Concepts and Administration for information about the impact of unrecoverable operations on a standby database |
If you have a read-only tablespace on read-only or slow media, then you may encounter errors or poor performance when performing media recovery with the USING BACKUP CONTROLFILE option. This situation occurs when the backup control file indicates that a tablespace was read/write when the control file was backed up. In this case, media recovery may attempt to write to the files. For read-only media, Oracle issues an error saying that it cannot write to the files. For slow media, such as a hierarchical storage system backed up by tapes, performance may suffer.
To avoid these recovery problems, use current control files rather than backups to recover the database. If you need to use a backup control file, then you can also avoid this problem if the read-only tablespace has not suffered a media failure.
You have these alternatives for recovering read-only and slow media when using a backup control file:
If a current or backup control file is unavailable for the recovery, then you can execute a CREATE CONTROLFILE statement as described in "Losing All Current and Backup Control Files". Read-only files should not be listed in the CREATE CONTROLFILE statement so that recovery can skip these files. No recovery is required for read-only files unless you restored backups of these files from a time when they were read/write.
After you create a new control file and attempt to mount and open the database, Oracle performs a data dictionary check against the files listed in the control file. Any files that were not listed in the CREATE CONTROLFILE statement but are present in the data dictionary have entries created for them in the control file. Oracle names these files as MISSINGnnnnn, where nnnnn is a five digit number starting with 0.
After the database is open, rename the read-only files to their correct filenames by executing the ALTER DATABASE RENAME FILE statement for all the files whose name is prefixed with MISSING.
To prepare for a scenario in which you might have to re-create the control file, run the following statement when the database is mounted or open to obtain the CREATE CONTROLFILE syntax:
ALTER DATABASE BACKUP CONTROLFILE TO TRACE;
This SQL statement produces a trace file that you can edit and then use as a script to re-create the control file in a recovery scenario. You can specify either the RESETLOGS or NORESETLOGS (default) keywords to generate CREATE CONTROLFILE ... RESETLOGS or CREATE CONTROLFILE ... NORESETLOGS versions of the script.
Note that all the restrictions related to read-only files in CREATE CONTROLFILE statements also apply to offline normal tablespaces, except that you need to bring the tablespace online after the database is open. You should leave out tempfiles from the CREATE CONTROLFILE statement and add them after database open.
| See Also:
"Backing Up the Control File to a Trace File" to learn about taking trace backups of the control file |
|
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|

