| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|





|
View PDF |
| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|
|
View PDF |
This chapter explains why statistics are important for the cost-based optimizer and how to gather and use statistics.
The chapter contains the following sections:
As database administrator, you can generate statistics that quantify the data distribution and storage characteristics of tables, columns, indexes, and partitions. The cost-based optimization approach uses these statistics to calculate the selectivity of predicates and to estimate the cost of each execution plan. Selectivity is the fraction of rows in a table that the SQL statement's predicate chooses. The optimizer uses the selectivity of a predicate to estimate the cost of a particular access method and to determine the optimal join order and join method.
The statistics are stored in the data dictionary and can be exported from one database and imported into another. For example, you might want to transfer your statistics to a test system to simulate your production environment.
|
Note: The statistics mentioned in this section are CBO statistics, not instance performance statistics visible through |
You should gather statistics periodically for objects where the statistics become stale over time because of changing data volumes or changes in column values. New statistics should be gathered after a schema object's data or structure are modified in ways that make the previous statistics inaccurate. For example, after loading a significant number of rows into a table, collect new statistics on the number of rows. After updating data in a table, you do not need to collect new statistics on the number of rows, but you might need new statistics on the average row length.
Use the DBMS_STATS package to generate statistics.
Statistics generated include the following:
Because the cost-based approach relies on statistics, you should generate statistics for all tables and clusters and all indexes accessed by your SQL statements before using the cost-based approach. If the size and data distribution of the tables change frequently, then regenerate these statistics regularly to ensure the statistics accurately represent the data in the tables.
Oracle generates statistics using the following techniques:
To perform an exact computation, Oracle requires enough space to perform a scan and sort of the table. If there is not enough space in memory, then temporary space might be required. For estimations, Oracle requires enough space to perform a scan and sort of only the rows in the requested sample of the table. For indexes, computation does not take up as much time or space.
Some statistics are computed exactly, such as the number of data blocks currently containing data in a table or the depth of an index from its root block to its leaf blocks.
Oracle Corporation recommends setting the ESTIMATE_PERCENT parameter of the DBMS_STATS gathering procedures to DBMS_STATS.AUTO_SAMPLE_SIZE to maximize performance gains while achieving necessary statistical accuracy. AUTO_SAMPLE_SIZE lets Oracle determine the best sample size for good statistics. For example, to collect table and column statistics for all tables in the OE schema with auto-sampling:
EXECUTE DBMS_STATS.GATHER_SCHEMA_STATS('OE',DBMS_STATS.AUTO_SAMPLE_SIZE);
To estimate statistics, Oracle selects a random sample of data. You can specify the sampling percentage and whether sampling should be based on rows or blocks. Oracle Corporation recommends using DBMS_STATS.AUTO_SAMPLE_SIZE for the sampling percentage. When in doubt, choose row sampling.
When you generate statistics for a table, column, or index, if the data dictionary already contains statistics for the object, then Oracle updates the existing statistics. Oracle also invalidates any currently parsed SQL statements that access the object.
The next time such a statement executes, the optimizer automatically chooses a new execution plan based on the new statistics. Distributed statements issued on remote databases that access the analyzed objects use the new statistics the next time Oracle parses them.
When you associate a statistics type with a column or domain index, Oracle calls the statistics collection method in the statistics type, if you analyze the column or domain index.
Partitioned schema objects can contain multiple sets of statistics. They can have statistics that refer to any of the following:
Unless the query predicate narrows the query to a single partition, the optimizer uses the global statistics. Because most queries are not likely to be this restrictive, it is most important to have accurate global statistics. Intuitively, it can seem that generating global statistics from partition-level statistics is straightforward; however, this is true only for some of the statistics. For example, it is very difficult to figure out the number of distinct values for a column from the number of distinct values found in each partition, because of the possible overlap in values. Therefore, actually gathering global statistics with the DBMS_STATS package is highly recommended, rather than calculating them with the ANALYZE statement.
|
Note: Oracle Corporation strongly recommends that you use the However, you must use the |
The PL/SQL package DBMS_STATS lets you generate and manage statistics for cost-based optimization. You can use this package to gather, modify, view, export, import, and delete statistics. You can also use this package to identify or name statistics gathered.
The DBMS_STATS package can gather statistics on indexes, tables, columns, and partitions, as well as statistics on all schema objects in a schema or database. It does not gather cluster statistics--you can use DBMS_STATS to gather statistics on the individual tables instead of the whole cluster.
The statistics-gathering operations can run either serially or in parallel. Index statistics are not gathered in parallel.
For partitioned tables and indexes, DBMS_STATS can gather separate statistics for each partition, as well as global statistics for the entire table or index. Similarly, for composite partitioning, DBMS_STATS can gather separate statistics for subpartitions, partitions, and the entire table or index. Depending on the SQL statement being optimized, the optimizer can choose to use either the partition (or subpartition) statistics or the global statistics.
DBMS_STATS gathers only statistics needed for cost-based optimization; it does not gather other statistics. For example, the table statistics gathered by DBMS_STATS include the number of rows, number of blocks currently containing data, and average row length, but not the number of chained rows, average free space, or number of unused data blocks.
See Also:
|
Table 3-1 lists the procedures in the DBMS_STATS package for gathering statistics:
| See Also:
Oracle9i Supplied PL/SQL Packages and Types Reference for syntax and examples of all |
System statistics enable the optimizer to consider a system's I/O and CPU performance and utilization. For each plan candidate, the optimizer computes estimates for I/O and CPU costs. It is important to know the system characteristics to pick the most efficient plan with optimal proportion between I/O and CPU cost.
System I/O characteristics depend on many factors and do not stay constant all the time. Using system statistics management routines, database administrators can capture statistics in the interval of time when the system has the most common workload. For example, database applications can process OLTP transactions during the day and run OLAP reports at night. Administrators can gather statistics for both states and activate appropriate OLTP or OLAP statistics when needed. This enables the optimizer to generate relevant costs with respect to available system resource plans.
When Oracle generates system statistics, it analyzes system activity in a specified period of time. Unlike table, index, or column statistics, Oracle does not invalidate already parsed SQL statements when system statistics get updated. All new SQL statements are parsed using new statistics. Oracle Corporation highly recommends that you gather system statistics.
The DBMS_STATS.GATHER_SYSTEM_STATS routine collects system statistics in a user-defined timeframe. You can also set system statistics values explicitly using DBMS_STATS.SET_SYSTEM_STATS. Use DBMS_STATS.GET_SYSTEM_STATS to verify system statistics.
Example 3-1 shows database applications processing OLTP transactions during the day and running reports at night. First, system statistics must be collected. The values in this example are user-defined; in other words, you must determine an appropriate time interval and name for your environment.
Gather statistics during the day. Gathering ends after 720 minutes and is stored in the mystats table:
BEGIN DBMS_STATS.GATHER_SYSTEM_STATS( gathering_mode => 'interval', interval => 720, stattab => 'mystats', statid => 'OLTP'); END; /
Gather statistics during the night. Gathering ends after 720 minutes and is stored in the mystats table:
BEGIN DBMS_STATS.GATHER_SYSTEM_STATS( gathering_mode => 'interval', interval => 720, stattab => 'mystats', statid => 'OLAP'); END; /
If appropriate, you can switch between the statistics gathered. It is possible to automate this process by submitting a job to update the dictionary with appropriate statistics.
During the day, the following jobs import the OLTP statistics for the daytime run:
VARIABLE jobno number; BEGIN DBMS_JOB.SUBMIT(:jobno, 'DBMS_STATS.IMPORT_SYSTEM_STATS(''mystats'',''OLTP'');' SYSDATE, 'SYSDATE + 1'); COMMIT; END; /
During the night, the following jobs import the OLAP statistics for the nighttime run:
BEGIN DBMS_JOB.SUBMIT(:jobno, 'DBMS_STATS.IMPORT_SYSTEM_STATS(''mystats'',''OLAP'');' SYSDATE + 0.5, 'SYSDATE + 1'); COMMIT; END; /
| See Also:
Oracle9i Supplied PL/SQL Packages and Types Reference for detailed information on the procedures in the |
Oracle can gather some statistics automatically while creating or rebuilding a B-tree or bitmap index. The COMPUTE STATISTICS option of CREATE INDEX or ALTER INDEX ... REBUILD enables this gathering of statistics.
The statistics that Oracle gathers for the COMPUTE STATISTICS option depend on whether the index is partitioned or nonpartitioned.
To ensure correctness of the statistics, Oracle always uses base tables when creating an index with the COMPUTE STATISTICS option, even if another index is available that could be used to create the index.
If you do not use the COMPUTE STATISTICS clause, or if you have made significant changes to the data, then use the DBMS_STATS.GATHER_INDEX_STATS procedure to collect index statistics.
| See Also:
Oracle9i SQL Reference for more information about the |
You should analyze the table after creating a function-based index, to allow Oracle to collect column statistics equivalent information for the expression. Optionally, you can collect histograms for the index expressions by specifying for all hidden columns size number_of_buckets in the METHOD_OPT argument to the DBMS_STATS procedures.
See Also:
|
Before gathering new statistics for a particular schema, use the DBMS_STATS.EXPORT_SCHEMA_STATS procedure to extract and save existing statistics. Then use DBMS_STATS.GATHER_SCHEMA_STATS to gather new statistics. You can implement both of these with a single call to the GATHER_SCHEMA_STATS procedure, by specifying additional parameters.
If key SQL statements experience significant performance degradation, then you can either gather statistics again using a larger sample size or perform the following steps:
DBMS_STATS.EXPORT_SCHEMA_STATS to save the new statistics in a different statistics table or a statistics table with a different statistics identifier.DBMS_STATS.IMPORT_SCHEMA_STATS to restore the old statistics. The application is now ready to run again.You might want to use the new statistics if they result in improved performance for the majority of SQL statements and if the number of problem SQL statements is small. In this case, perform the following steps:
DBMS_STATS.IMPORT_SCHEMA_STATS to restore the new statistics. The application is now ready to run with the new statistics. However, you will continue to achieve the previous performance levels for the problem SQL statements.You can automatically gather statistics or create lists of tables that have stale or no statistics. To automatically gather statistics, run the DBMS_STATS.GATHER_SCHEMA_STATS and DBMS_STATS.GATHER_DATABASE_STATS procedures with the OPTIONS and objlist parameters. Use the values listed in Table 3-2 for the options parameter.
The objlist parameter identifies an output parameter for the LIST STALE and LIST EMPTY options. The objlist parameter is of type DBMS_STATS.OBJECTTAB.
Before you can utilize automated statistics gathering for a particular table, you must bring either the tables of a specific schema or a complete database into the monitoring mode. Do this with the DBMS_STATS.ALTER_SCHEMA_TAB_MONITORING or DBMS_STATS.ALTER_DATABASE_TAB_MONITORING procedures. Alternatively, you can enable the monitoring attribute using the MONITORING keyword. This keyword is part of the CREATE TABLE and ALTER TABLE statement syntax. Monitoring tracks the approximate number of INSERTs, UPDATEs, and DELETEs for that table since the last time statistics were gathered. Oracle uses this data to identify tables with stale statistics. Then, you can enable automated statistics gathering by setting up a recurring job (perhaps by using job queues) that invokes DBMS_STATS.GATHER_TABLE_STATS with the GATHER STALE option at an appropriate interval for your application.
Objects are considered stale when 10% of the total rows have been changed. When you issue GATHER_TABLE_STATS with GATHER STALE, the procedure checks the USER_TAB_MODIFICATIONS view. If a monitored table has been modified more than 10%, then statistics are gathered again. The information about changes of tables, as shown in the USER_TAB_MODIFICATIONS view, can be flushed from the SGA into the data dictionary with the DBMS_STATS.FLUSH_DATABASE_MONITORING_INFO procedure.
To disable monitoring, use the DBMS_STATS.ALTER_SCHEMA_TAB_MONITORING or DBMS_STATS.ALTER_DATABASE_TAB_MONITORING procedures, or use the NOMONITORING keyword.
| See Also:
Oracle9i SQL Reference for more information about the |
The GATHER STALE option gathers statistics only for tables that have stale statistics and for which you have enabled monitoring.
The GATHER STALE option maintains up-to-date statistics for the cost-based optimizer. Using this option at regular intervals also avoids the overhead associated with gathering statistics on all tables at one time. The GATHER option can incur much more overhead, because this option generally gathers statistics for a greater number of tables than GATHER STALE.
Use a script or job scheduling tool for the GATHER_SCHEMA_STATS and GATHER_DATABASE_STATS procedures to establish a frequency of statistics collection that is appropriate for the application. The frequency of collection intervals should balance the task of providing accurate statistics for the optimizer against the processing overhead incurred by the statistics collection process.
You can use the GATHER_SCHEMA_STATS and GATHER_DATABASE_STATS procedures to create a list of tables with stale statistics. You can also use these procedures to create a list of tables with no statistics. Use the lists to identify tables for which you want to gather manual statistics.
You can preserve versions of statistics for tables by specifying the stattab, statid, and statown parameters in the DBMS_STATS package. Use stattab to identify a destination table for archiving previous versions of statistics. Further identify these versions using statid to denote the date and time the version was made. Use statown to identify a destination schema, if it is different from the schema(s) of the actual tables. You must first create such a table, using the CREATE_STAT_TABLE procedure of the DBMS_STATS package.
| See Also:
Oracle9i Supplied PL/SQL Packages and Types Reference for more information on |
You can use the ANALYZE statement to generate statistics for cost-based optimization.
|
Note: Oracle Corporation strongly recommends that you use the However, you must use the |
The statistics gathered help you determine how the data is distributed across the tables. The optimizer assumes that the data is uniformly distributed. You can analyze the actual data distribution in the tables by viewing the appropriate dictionary table: DBA_TABLES for tables and DBA_TAB_COL_STATISTICS for column statistics.
You can use histograms to determine attribute skew.
When statistics do not exist, the optimizer uses the default values shown in Table 3-4 and Table 3-4.
| Index Statistic | Default Value Used by Optimizer |
|---|---|
|
|
1 |
|
|
25 |
|
|
1 |
|
|
1 |
|
|
100 |
|
|
800 (8 * number of blocks) |
This section provides guidelines on how to use and view statistics. This includes:
This section describes statistics tables and lists the views that display information about statistics stored in the data dictionary.
The DBMS_STATS package lets you store statistics in a statistics table. You can transfer the statistics for a column, table, index, or schema into a statistics table and subsequently restore those statistics to the data dictionary. The optimizer does not use statistics that are stored in a statistics table.
Statistics tables enable you to experiment with different sets of statistics. For example, you can back up a set of statistics before you delete them, modify them, or generate new statistics. You can then compare the performance of SQL statements optimized with different sets of statistics, and if the statistics stored in a table give the best performance, you can restore them to the data dictionary.
A statistics table can keep multiple distinct sets of statistics, or you can create multiple statistics tables to store distinct sets of statistics separately.
Use the DBMS_STATS package to view the statistics stored in the data dictionary or in a statistics table. Example 3-2 queries a statistics table.
DECLARE num_rows NUMBER; num_blocks NUMBER; avg_row_len NUMBER; BEGIN -- retrieve the values of table statistics on OE.ORDERS -- statistics table name: OE.SAVESTATS statistics ID: TEST1 DBMS_STATS.GET_TABLE_STATS('OE','ORDERS',null, 'SAVESTATS','TEST1', num_rows,num_blocks,avg_row_len); -- print the values DBMS_OUTPUT.PUT_LINE('num_rows='||num_rows||',num_blocks='||num_blocks|| ',avg_row_len='||avg_row_len); END;
|
Note: Statistics held in a statistics table are held in a form that is only understood by using |
To view statistics in the data dictionary, query the appropriate data dictionary view (USER_, ALL_, or DBA_). The following list shows the DBA_ views:
DBA_TABLESDBA_TAB_COL_STATISTICSDBA_INDEXESDBA_CLUSTERSDBA_TAB_PARTITIONSDBA_TAB_SUBPARTITIONSDBA_IND_PARTITIONSDBA_IND_SUBPARTITIONSDBA_PART_COL_STATISTICSDBA_SUBPART_COL_STATISTICS
| See Also:
Oracle9i Database Reference for information on the statistics in these views |
To verify that the table statistics are available, query the data dictionary view DBA_TABLES, using a statement like the one in Example 3-3:
SQL> SELECT TABLE_NAME, NUM_ROWS, BLOCKS, AVG_ROW_LEN, TO_CHAR(LAST_ANALYZED, 'MM/DD/YYYY HH24:MI:SS') FROM DBA_TABLES WHERE TABLE_NAME IN ('SO_LINES_ALL','SO_HEADERS_ALL','SO_LAST_ALL');
This returns the following typical data:
TABLE_NAME NUM_ROWS BLOCKS AVG_ROW_LEN LAST_ANALYZED ------------------------ -------- ------- ----------- ------------------- SO_HEADERS_ALL 1632264 207014 449 07/29/1999 00:59:51 SO_LINES_ALL 10493845 1922196 663 07/29/1999 01:16:09 SO_LAST_ALL ...
To verify that index statistics are available and decide which are the best indexes to use in an application, query the data dictionary view DBA_INDEXES, using a statement like the one in Example 3-4:
SQL> SELECT INDEX_NAME "NAME", NUM_ROWS, DISTINCT_KEYS "DISTINCT", 1 LEAF_BLOCKS, CLUSTERING_FACTOR "CF", BLEVEL "LEVEL", 2 AVG_LEAF_BLOCKS_PER_KEY "ALFBPKEY" 3 FROM DBA_INDEXES 4 WHERE OWNER = 'SH' 5* ORDER BY INDEX_NAME;
Typical output is:
NAME NUM_ROWS DISTINCT LEAF_BLOCKS CF LEVEL ALFBPKEY -------------------------- -------- -------- ----------- ------- ------- ---------- CUSTOMERS_PK 50000 50000 454 4405 2 1 PRODUCTS_PK 10000 10000 90 1552 1 1 PRODUCTS_PROD_CAT_IX 10000 4 99 4422 1 24 PRODUCTS_PROD_SUBCAT_IX 10000 37 170 6148 2 4 SALES_PROD_BIX 6287 909 1480 6287 1 1 SALES_PROMO_BIX 4727 459 570 4727 1 1 6 rows selected.
The optimizer uses the following criteria when determining which index to use:
CF). This is the collocation amount of the index block relative to data blocks. The higher the CF, the less likely the optimizer is to select this index.ALFBKEY). Average number of leaf blocks in which each distinct value in the index appears, rounded to the nearest integer. For indexes that enforce UNIQUE and PRIMARY KEY constraints, this value is always one.Use the following notes to assist you in deciding whether you have chosen an appropriate index for a table, data, and query:
Consider index ap_invoices_n3, having two distinct keys. The resulting selectivity based on index ap_invoices_n3 is poor, and the optimizer is not likely to use this index. Using this index fetches 50% of the data in the table. In this case, a full table scan is cheaper than using index ap_invoices_n3.
The optimizer uses alphabetic determination. If the optimizer determines that the selectivity, cost, and cardinality of two finalist indexes is the same, then it looks at the names of the indexes and chooses the name that begins with the lower alphabetic letter or number.
To verify that column statistics are available, query the data dictionary view DBA_TAB_COL_STATISTICS, using a statement like the one in Example 3-5:
SQL> SELECT COLUMN_NAME, NUM_DISTINCT, NUM_NULLS, NUM_BUCKETS, DENSITY FROM DBA_TAB_COL_STATISTICS WHERE TABLE_NAME ="PA_EXPENDITURE_ITEMS_ALL" ORDER BY COLUMN_NAME;
This returns the following data:
COLUMN_NAME NUM_DISTINCT NUM_NULLS NUM_BUCKETS DENSITY ------------------------------ ------------ ---------- ----------- ---------- BURDEN_COST 4300 71957 1 .000232558 BURDEN_COST_RATE 675 7376401 1 .001481481 CONVERTED_FLAG 1 16793903 1 1 COST_BURDEN_DISTRIBUTED_FLAG 2 15796 1 .5 COST_DISTRIBUTED_FLAG 2 0 1 .5 COST_IND_COMPILED_SET_ID 87 6153143 1 .011494253 EXPENDITURE_ID 1171831 0 1 8.5337E-07 TASK_ID 8648 0 1 .000115634 TRANSFERRED_FROM_EXP_ITEM_ID 1233787 15568891 1 8.1051E-07
Verifying column statistics are important for the following conditions:
WHERE clause includes a column(s) with a bind variable; for example: column x = :variable_yIn these cases, you can use the stored column statistics to get a representative cardinality estimation for the given expression.
The following subsections examine the data returned by the query in Example 3-5.
NUM_DISTINCT indicates the number of distinct values for a column.
In Example 3-5, the number of distinct values for the column CONVERTED_FLAG is 1. In this case, this column has only one value. If there is a bind variable on column CONVERTED_FLAG in the WHERE clause (for example, CONVERTED_FLAG =:variable_y), then this leads to poor selectivity, and CONVERTED_FLAG is a poor candidate to be used as the index.
Column COST_BURDEN_DISTRIBUTED_FLAG: NUM_DISTINCT = 2. Likewise, this value is low. COST_BURDEN_DISTRIBUTED_FLAG is not a good candidate for an index unless there is much skew or there are a lot of nulls. If there is data skew of, say, 90%, then 90% of the data has one particular value and 10% of the data has another value. If the query only needs to access the 10%, then a histogram is needed on that column in order for the optimizer to recognize the skew and use an index on this column.
In Example 3-5, NUM_DISTINCT is more than 1 million for column EXPEDITURE_ID. If there is a bind variable on column EXPENDITURE_ID, then this leads to high selectivity (implying high density of data on this column). In other words, EXPENDITURE_ID is a good candidate to be used as the index.
NUM_NULLS indicates the number of null values for that column.
If a single column index has few nulls, such as the COST_DISTRIBUTED_FLAG column in Example 3-5, and if this column is used as the index, then the resulting data set is large.
If there are many nulls on a particular column, such as the CONVERTED_FLAG column in Example 3-5, and if this column is used as the index, then the resulting data set is small. This means that COST_DISTRIBUTED_FLAG is a more appropriate column to index.
This indicates the density of the values of that column. This is calculated as 1 divided by NUM_DISTINCT.
Column statistics are useful to help determine the most efficient join method, which, in turn, is also based on the number of rows returned.
The cost-based optimizer can use data value histograms to get accurate estimates of the distribution of column data. A histogram partitions the values in the column into bands, so that all column values in a band fall within the same range. Histograms provide improved selectivity estimates in the presence of data skew, resulting in optimal execution plans with nonuniform data distributions.
One of the fundamental tasks of the cost-based optimizer is determining the selectivity of predicates that appear in queries. Selectivity estimates are used to decide when to use an index and the order in which to join tables. Some attribute domains (a table's columns) are not uniformly distributed.
The cost-based optimizer uses height-based histograms on specified attributes to describe the distributions of nonuniform domains. In a height-based histogram, the column values are divided into bands so that each band contains approximately the same number of values. The useful information that the histogram provides, then, is where in the range of values the endpoints fall.
Consider a column C with values between 1 and 100 and a histogram with 10 buckets. If the data in C is uniformly distributed, then the histogram looks similar to Figure 3-1, where the numbers are the endpoint values.
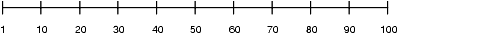
The number of rows in each bucket is one tenth the total number of rows in the table. Four-tenths of the rows have values between 60 and 100 in this example of uniform distribution.
If the data is not uniformly distributed, then the histogram might look similar to Figure 3-2.
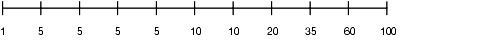
In this case, most of the rows have the value 5 for the column; only 1/10 of the rows have values between 60 and 100.
Histograms can affect performance and should be used only when they substantially improve query plans. Histogram statistics data is persistent, so the space required to save the data depends on the sample size. In general, create histograms on columns that are used frequently in WHERE clauses of queries and have a highly skewed data distribution. For uniformly distributed data, the cost-based optimizer can make fairly accurate guesses about the cost of executing a particular statement without the use of histograms.
Histograms, like all other optimizer statistics, are static. They are useful only when they reflect the current data distribution of a given column. (The data in the column can change as long as the distribution remains constant.) If the data distribution of a column changes frequently, you must recompute its histogram frequently.
Histograms are not useful for columns with the following characteristics:
You generate histograms by using the DBMS_STATS package. You can generate histograms for columns of a table or partition. For example, to create a 10-bucket histogram on the SAL column of the emp table, issue the following statement:
EXECUTE DBMS_STATS.GATHER_TABLE_STATS ('scott','emp', METHOD_OPT => 'FOR COLUMNS SIZE 10 sal');
The SIZE keyword declares the maximum number of buckets for the histogram. You would create a histogram on the SAL column if there were an unusually high number of employees with the same salary and few employees with other salaries. You can also collect histograms for a single partition of a table.
Oracle Corporation recommends using the DBMS_STATS package to have the database automatically decide which columns need histograms. This is done by specifying SIZE AUTO.
| See Also:
Oracle9i Supplied PL/SQL Packages and Types Reference for more information on the |
If the number of frequently occurring distinct values in a column is relatively small, then set the number of buckets to be greater than that number. The default number of buckets for a histogram is 75. This value provides an appropriate level of detail for most data distributions. However, because the number of buckets and the data distribution both affect a histogram's usefulness, you might need to experiment with different numbers of buckets to obtain optimal results.
There are two types of histograms:
Height-based histograms place approximately the same number of values into each range, so that the endpoints of the range are determined by how many values are in that range. Only the last (largest) values in each bucket appear as bucket (end point) values.
Consider that a table's query results in the following four sample values: 4, 18, 30, and 35.
For a height-based histogram, each of these values occupies a portion of one bucket, in proportion to their size. The resulting selectivity is computed with the following formula:
S = Height(35) / Height(4 + 18 + 30 + 35)
Value-based histograms are created when the number of distinct values is less than or equal to the number of histogram buckets specified. In value-based histograms, all the values in the column have corresponding buckets, and the bucket number reflects the repetition count of each value. These can also be known as frequency histograms.
Consider the same four sample values in the previous example. In a value-based histogram, a bucket is used to represent each of the four distinct values. In other words, one bucket represents 4, one bucket represents 18, another represents 30, and another represents 35. The resulting selectivity is computed with the following formula:
S = [#rows(35)/(#rows(4) + #rows(18) + #rows(30) + #rows(35))] / #buckets
If there are many different values anticipated for a particular column of table, it is preferable to use the value-based histogram rather than the height-based histogram. This is because if there is much data skew in the height, then the skew can offset the selectivity calculation and give a nonrepresentative selectivity value.
Example 3-6 illustrates the use of a histogram in order to improve the execution plan and demonstrate the skewed behavior of the s6 indexed column.
UPDATE so_lines l SET open_flag=null, s6=10, s6_date=sysdate, WHERE l.line_type_code in ('REGULAR','DETAIL','RETURN') AND l.open_flag = 'Y' AND NVL(l.shipped_quantity, 0)=0 OR NVL(l.shipped_quantity, 0) != 0 AND l.shipped_quantity +NVL(l.cancelled_quantity, 0)= l.ordered_quantity)) AND l.s6=18
This query shows the skewed distribution of data values for s6. In this case, there are two distinct non-null values: 10 and 18. The majority of the rows consists of s6 = 10 (1,589,464), while a small number of rows consist of s6 = 18 (13,091).
S6: COUNT(*) ====================== 10 1,589,464 18 13,091 NULL 21,889
The selectivity of column s6, where s6 = 18:
S = 13,091 / (13,091 + 1,589,464) = 0.008
If No Histogram is Used: The selectivity of column s6 is assumed to be 50%, uniformly distributed across 10 and 18. This is not selective; therefore, s6 is not an ideal choice for use as an index.
If a Histogram is Used: The data distribution information is stored in the dictionary. This allows the optimizer to use this information and compute the correct selectivity based on the data distribution. In Example 3-6, the selectivity, based on the histogram data, is 0.008. This is a relatively high, or good, selectivity, which leads the optimizer to use an index on column s6 in the execution plan.
To view histogram information, query the appropriate data dictionary view (USER_, ALL_, or DBA_). The following list shows the DBA_ views:
View the DBA_HISTOGRAMS dictionary table for the number of buckets (in other words, the number of rows) for each column:
ENDPOINT_NUMBERENDPOINT_VALUE
| See Also:
Oracle9i Database Reference for column descriptions of data dictionary views, as well as histogram use and restrictions |
To verify that histogram statistics are available, query the data dictionary's DBA_HISTOGRAMS table, using a statement similar to Example 3-7.
SQL> SELECT ENDPOINT_NUMBER, ENDPOINT_VALUE FROM DBA_HISTOGRAMS WHERE TABLE_NAME ="SO_LINES_ALL" AND COLUMN_NAME="S2" ORDER BY ENDPOINT_NUMBER;
This query returns the following typical data:
ENDPOINT_NUMBER ENDPOINT_VALUE --------------- --------------- 1365 4 1370 5 2124 8 2228 18
One row corresponds to one bucket in the histogram. Consider the differences between ENDPOINT_NUMBER values in Example 3-7 listed in Table 3-5.
| Bucket (values) | ENDPOINT_NUMBER Difference |
Number of Values in Bucket |
|---|---|---|
|
1 (0 to 4) |
N/A |
N/A |
|
2 (4 to 5) |
1370 - 1365 |
5 |
|
3 (5 to 8) |
2124 - 1370 |
754 |
|
4 (8 to 18) |
2228 - 2124 |
104 |
Table 3-5 shows that the buckets hold very different numbers of values. The data is skewed: 754 values are between 5 and 8, but only 104 are between 8 and 18. More buckets should be used.
|
 Copyright © 2000, 2002 Oracle Corporation. All Rights Reserved. |
|

